我在2018年中的时候开始接触 kubernetes ,并主导过传统应用向容器化方向的转换工作。
结合落地过程中遇到的实际问题,以及相应的故障处理经验,我来讲一下要如何更好地管理TKE集群。
集群管理
其实使用TKE之前,应该先问自己一个问题。这个问题叫做准备好面对疾风了吗 ?Oh no,应该叫做你真的适合 kubernetes 吗?

一开始接触 kubernetes 的时候,我被它自动伸缩,应用自愈,快速迭代,版本回滚,负载均衡等特性深深吸引,但当我接触并使用一段时间之后,被应用性能监控,节点故障,网络诊断折磨得死去活来。
最有印象的是,当时有一个JAVA开发工程师这么质问我:“我的应用在本地和云服务器上面跑都没有问题,为什么容器化之后响应就变慢。这些都是你的问题。”
之后我特意花了点时间,长时间关注并监控这个JAVA应用,直到我找到 OOM kill 以及响应变慢的原因,并花了一个周六的时间,修复内存泄露这个代码问题之后,世界终于恢复了往日的和平。
是的,这不是 kubernetes 的问题,这也是 kubernetes 的问题。程序设计素有没有银弹这种说法。所谓的简便,不过是把复杂性转移到别的地方。应用的最终一致性,是靠各种各样的 Controller 调谐,而所谓的负载均衡,则是遍布所有节点的各种 IPtable 规则,应用的重启则是靠节点上勤劳的 kubelet 。
所以,如果你没有勇气应对容器化带来的全新挑战,又或者应用规模非常地小,迭代次数不频繁,那我还是不建议各位趟这波浑水。

“拿着一把锤子,看见什么都是钉子。”这是病,得治。而只有真正的勇士,才敢于直面惨淡的人生。
集群规划
凡事预则立,不预则废。关于集群的部署,我们的官方文档其实已经说得比较详细了,我觉得集群规划比较重要的地方在于容器运行时和网络插件的选择。
我个人认为,从业务前瞻性来讲,containerd 会比 docker 好一点,因为谷歌和 docker 公司利益不同。kubernetes 在一开始立项的时候就以 CRI 的形式确立了容器运行时的标准,而不是把 docker 直接拿来用,这个动作是有隐喻的。这个伏笔就是在 kubernetes 1.20 里面将放弃对 docker 的支持。
而网络插件,得结合平台和应用特性而定。以腾讯云为例,目前我们支持GlobalRouter 和 VPC-CNI。简单地说,VPC-CNI的网络性能会更好一些,但会受限于机器核心数,如果应用的特性以小型微服务(内存占用1G以内)为主,那么使用GlobalRouter 会合适一点。
除此以外,容器网络的CIDR也是一个痛点,如果CIDR设置的范围太小,那么可分配的pod/service IP过少,也会影响最终的应用规模。
灾备方案
曾经有一个美好的 namespace 放在我面前我没有珍惜,直到我误删了她的时候才知道一切都已太迟。如果上天能给我一次再来一次的机会,我真的希望那个时候的我脑子没有进水。

我还记得那次的事故,为了恢复整体业务的可用,连累了半个技术部加班到很晚。但在恢复营业的过程中,其实也发现了以前一些工作不到位的地方:比如给开发修改某个 namespace 内资源的权限,结果开发更新应用为了方便,直接修改YAML里面的ENV,但是后来又把配置忘了;比如对 kubernetes YAML没有备份等。
结合一整个应用的交付流程,我后来做了一个比较简便的方案:
- 对代码服务器的磁盘进行周期性备份
- 对kuber YAML 用kube-backup同步到 git 仓库
- 拉取镜像的账户只配置了
pull image权限 - 把生产级别的资源放到default namespace里面(因为这个默认
namespaces是不能删除的) - 关闭了开发的修改权限,配置全部走配置中心,并且移除了大部分的configmap
- 关闭了我自己的 admin 账号,分配了一个没有删除权限的
api-server证书
关于第5点是有争议的。我个人认为,当我们依赖某种技术的时候,应该考虑“反依赖性”。反依赖性是指如果这种技术过时,或者出现严重的问题时,我们的 plan B 是什么?
虽然 kubernetes 提供了热更新的一个机制,但是为了减轻 ETCD 的负担,也为了减少对 kubernetes 的依赖,我们把配置放到了 consul 那边。
上医治未病,下医治已病。希望大家不要像我这样,等到问题出现时,才想着怎么解决问题。
节点管理
TKE的节点资源规划其实是一个有点复杂的「费米估算」问题,合理地管理规划节点,有助于更好地降本增效。
节点配置,需要切合实际情况。像是计算密集型的应用,就要分配多一点CPU,而内存消耗性应用,我个人偏好4核32G的节点多一点。
对节点有特殊要求的服务可使用节点亲和性(Node Affinity)部署,以便调度到符合要求的节点。例如,让 MySQL 调度到高 IO 的机型以提升数据读写效率。
而GPU型节点一般是有特殊用途的,把它们跟普通节点一起向用户交付是不合适的。所以我一般建议用节点污点跟其他节点做隔离,确保特殊类型的节点不会运行不符合预期的容器。
1
kubectl taint node $no just-for-gpu-application=true:NoExecute
1
2
3
4
5
6
7
tolerations:
- key: "just-for-gpu-application"
operator: "Exists"
effect: "NoSchedule"
- key: "just-for-gpu-application"
operator: "Exists"
effect: "NoExecute"
我个人其实不建议在 kubernetes 集群里面加入小配置的节点(比如1核2G这样的配置),因为这样会损失应用伸缩的“弹性”,比如一个应用一开始给了0.7核1.5G,但运行一段时间之后发现要2核4G的配置,这样重新调度就只能放弃原有节点。而且这种低配置的节点其实也不是很符合分布式系统的设计理念——靠资源的冗余实现高可用性。
那么节点的配置是不是越高越好呢?
这个问题其实没有一个标准的答案。但我多次遇过因为节点 docker hang 或者 Not Ready ,甚至是节点负载过高,而导致的整体节点故障问题。这会引发节点上面所有应用的雪崩和不可用。
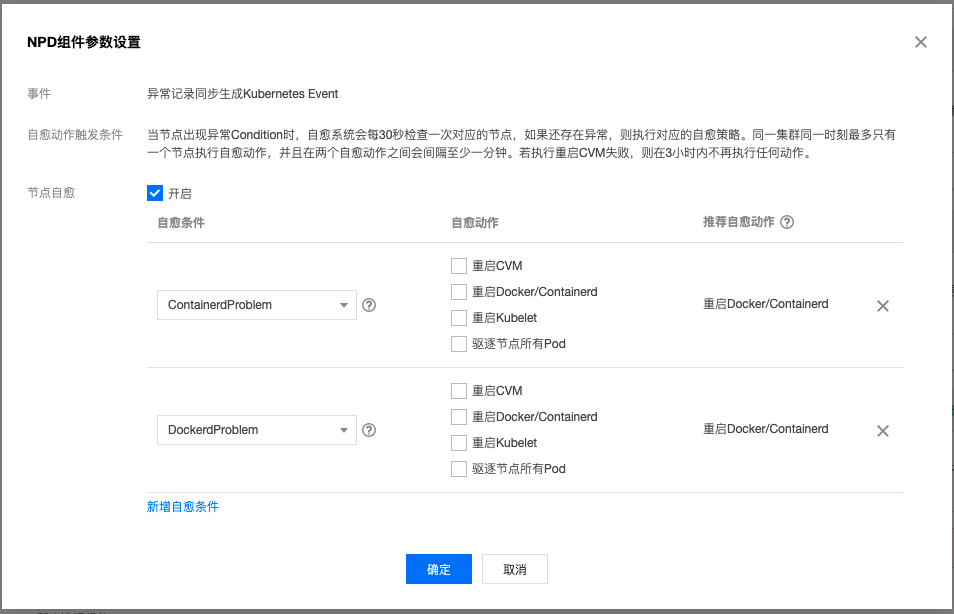
针对单点节点故障而导致的问题,除了在云监控上面建立相应的告警策略外, 我们在社区版本的基础上,对NPD做了增强。支持节点自愈(具体见《使用 TKE NPDPlus 插件增强节点的故障自愈能力》),用户可以选择重启容器运行时甚至重启CVM。
除此以外,我们TKE还支持使用置放群组从物理层面实现容灾,从云服务器底层硬件层面,利用反亲和性将 Pod 打散到不同节点上。
业务管理
kubernetes 这套 DevOps 系统对运维和研发都是一种挑战。研发要适应 pod 这种朝生夕死的架构,拥抱应用容器化带来的变化。
易失性
只是一切都将逝去。
在我的世界里,这或许是唯一可以视为真理的一句话。 《人间失格》
易失性有几个理解。首先,研发要适应容器的IP是变动的,其次,文件系统也是变动的。以往当代码部署在CVM上面的时候,我们可以在服务器上安装各种调试工具,但是在容器的环境,就会面临两难的选择:是把调试工具打包进镜像,还是用 kubectl exec 进入容器安装。
如果把工具打包进容器,那么就会让镜像带上一些业务无关的内容,导致镜像更大,发布慢一点;而如果把调试工具放在容器里面安装,则会面临每次更新/重启都需要做大量重复工作。
这里我同样不会给出标准答案,但我会告诉大家在另外几个维度,业务的管理可以怎么去做。
可观察性
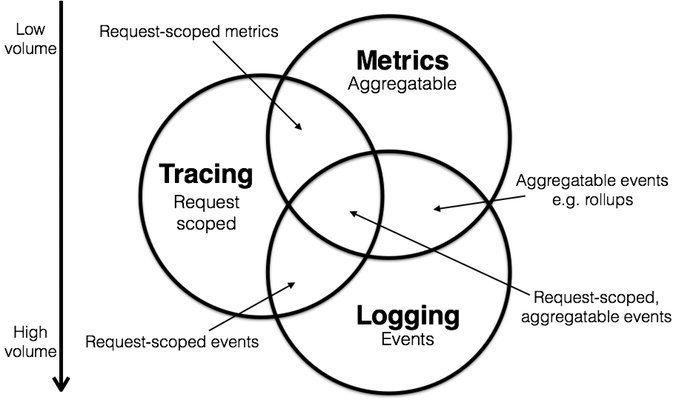
目前业界对可观察性的看法是将其分为
- Metrics
- Tracing
- Logging
这几部分。在这一方面,我们腾讯云基于 Prometheus 做了一套云原生监控的方案,以及日志采集 , 事件存储。这几套方案涵盖了指标监控,日志采集,事件存储和监控告警等各个方面。
而从 Tracing 角度方面考虑,分布式服务的跟踪监测我觉得还可以再细分为非侵入式和侵入式的方案。侵入式的方案指的是修改代码,比如在请求的链路里面加入特定请求头,request header;非侵入式方案则是现在很流行的 Service Mesh方案,让业务更加注重于业务,而让流量管控交给 sidecar 。由于篇幅限制,这里就不过多展开了。
隔离性
资源隔离性
资源的隔离性,其实也能继续细分为同集群内资源的隔离和多租户的隔离。在之前的章节中,我已经提到了用节点污点隔离普通节点和GPU节点,这其实就是一种资源隔离的方式。
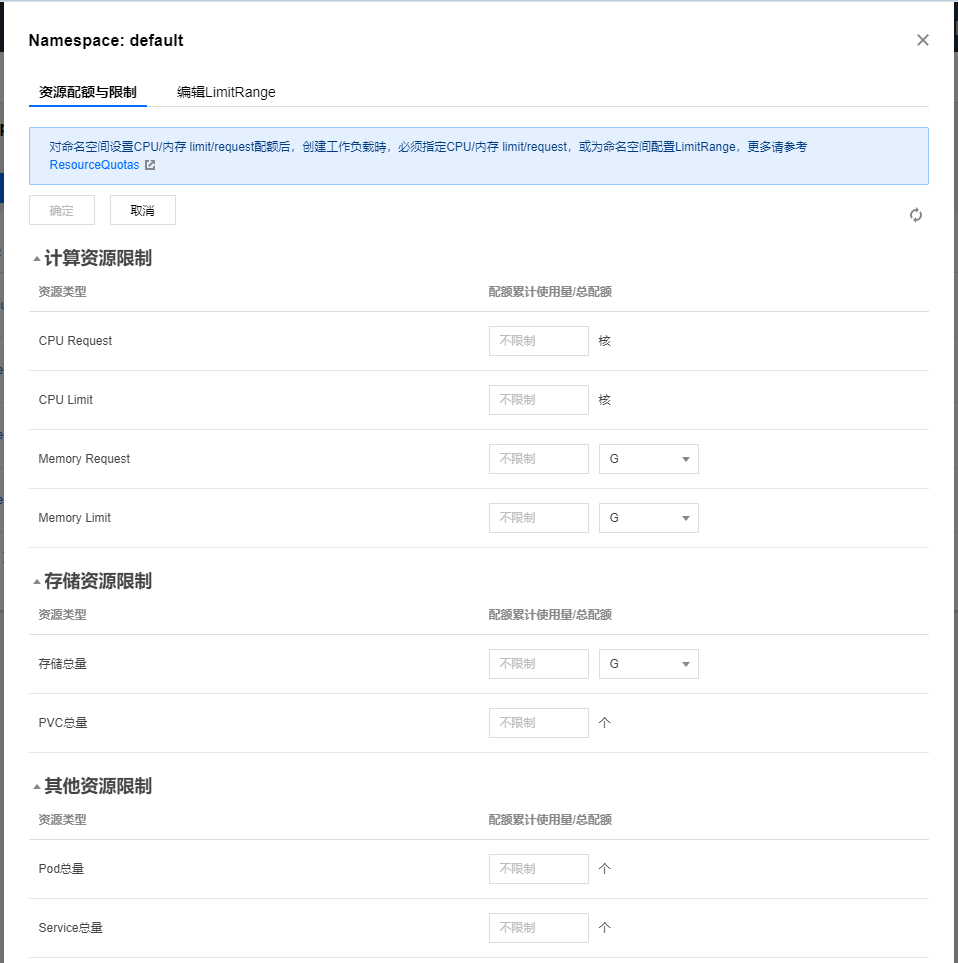
而多租户,最简单的实现莫过于一个用户一个 namespace ,然后用 LimitRange 限制。
资源的隔离性不仅存在于集群内,也存在于集群外。有时候我们会在同一个 VPC 或者跨 VPC 建集群,以实现彻底的资源隔离性,但是这种做法,也会产生跨云通讯的新问题(在VPC层面,我们支持通过对等连接和云联网通信)。这对整个微服务架构,会是一种新的挑战。
网络隔离性
理解网络隔离性,要反过来先理解网络连通性。以 Flannel 的 VXLAN 模式为例,采用这个模式的 kubernetes 集群节点之间是互联的。而且实际上,跨 namespace 的 service 也是互联的。
这里也许有人有个疑问:不是说 kubernetes 是基于 namespace 做的资源隔离吗?为什么说跨 namespace 的访问是互联的?
这里就不得不提到 kubernetes 注入的这个 /etc/resolv.conf 文件,以 default 下面随便一个未修改过网络配置的 pod 为例:
1
2
3
4
cat /etc/resolv.conf
nameserver <kube-dns-vip>
search default.svc.cluster.local svc.cluster.local cluster.local localdomain
options ndots:5
这个配置的意思是五级域名以下走 coreDNS ,优先按照 search 顺序补全。比如解析百度是这样:
1
2
3
4
5
6
7
sh-4.2# host -v baidu.com
Trying "baidu.com.<namespace>.svc.cluster.local"
Trying "baidu.com.svc.cluster.local"
Trying "baidu.com.cluster.local"
Trying "baidu.com.localdomain"
Trying "baidu.com"
......
这里其实就可以看出端倪。比如我们在 default 和 kube-system 下面同时建立了一个名为 tke-six-six-six 的服务,在 default 下面之所以访问 six 不会跳到 kube-system 定义的服务,是因为一开始尝试解析的就是 tke-six-six-six.default.svc.cluster.local ,而如果直接访问 tke-six-six-six.kube-system.svc.cluster.local ,也是可以的。所谓的隔离只是在域名解析那里做了手脚。
网络的隔离性,在多租户环境下显得尤为重要。我们不能保证来往的流量都是合法的,那就先假定所有的流量都是非法的,只让符合要求的流量接入应用。如果不用 istio 的话,其实官方也基于ip,namespaceSelector和podSelector做了 Network Policy。
自愈性
这里再次套用分布式系统的第一性原理——通过资源的冗余实现系统的可用。一般为了规避单一节点的不可用,我们会建议用户对应用设置2以上的副本并设置 podAntiAffinity 。
1
2
3
4
5
6
7
8
9
10
11
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- my-pipi-server
topologyKey: kubernetes.io/hostname
weight: 100
除此以外,一般我们会建议用户加上以下配置
- readinessProbe(就绪检查)
- livenessProbe(健康检查)
- preStop hook
就绪检查和健康检查的重要性自不必说,preStop hook 可以设置 sleep 一小段的时间,因为 kube-proxy 更新节点转发规则的动作并不是及时的,给 Pod 中的 container 添加 preStop hook,使 Pod 真正销毁前先 sleep 等待一段时间,留出时间给 Endpoint controller 和 kube-proxy 更新 Endpoint 和转发规则。
注意 terminationGracePeriodSeconds 的默认设置是30秒。如果preStop hook 设置的时间超过30秒,那么 terminationGracePeriodSeconds 的值也要做相应改变。
总结
纸上得来终觉浅,绝知此事要躬行。容器化对运维和开发都有新的考验,切不可掉以轻心。
希望大家不管是运维也好,开发也罢,能在运维中提炼管理的技巧,在开发中解锁新的 翻车编程 招式。

没有问题才是最大的问题,没有答案,就自己找答案!
参考链接
[1] Introducing Container Runtime Interface (CRI) in Kubernetes https://kubernetes.io/blog/2016/12/container-runtime-interface-cri-in-kubernetes/
[2] K8s宣布弃用Docker,千万别慌! https://cloud.tencent.com/developer/article/1758588
[3] 解读:云原生下的可观察性发展方向 https://cloudnative.to/blog/cloud-native-observability/
[4] 十分钟漫谈容器网络方案 01—Flannel https://www.infoq.cn/article/rnbqhui1wipzj6bjiwet