摘要
本文从形式逻辑与定义出发(网络效应、熵增定律、反依赖性、边际收益为零的「0」哲学),系统梳理了 2014–2025 年间阿里云、谷歌云、Azure、Cloudflare、腾讯云等主流公有云与基础设施的重大故障记录,并比较了各家的故障透明度。在此基础上,文章分析了公有云「死因」:软件熵增与边际收益为零导致旧代码与架构难以治理,网络效应在故障时放大连锁反应,而 SLA 赔付与政企实际损失严重不对等。作者建议大型政企将对公有云的「反依赖」提上日程,并提出「小并发高可用系统」的设想——通过存储冗余与流量分摊(如多区域、多集群 DNS 解析)降低单点风险与问题扩散半径。
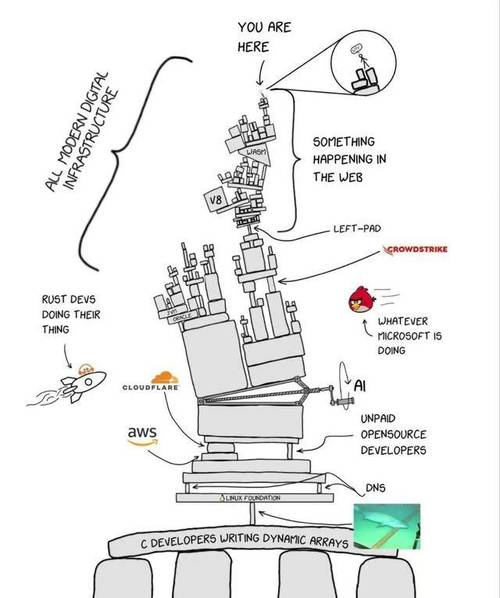
形式逻辑和定义
网络效应:一个产品/服务/平台的使用者(或参与者)越多,它对每一个使用者的价值就越大。
熵增定律:项目代码库会随着时间推移而变成一座屎山。
反依赖性:对单一编程语言/技术栈/云平台的反向依赖。比如多语言混合编程,多技术栈选型,多云策略。反依赖性让业务可以脱离语言/开源项目/公有云平稳运行。
0:边际收益为0的代码重构没人愿意做。
AWS的故障
| 时间 | 地域/范围 | 持续时长 | 主要影响范围与后果 | 官方/主流原因说明 | 备注 / 行业评价 |
|---|---|---|---|---|---|
| 2014-06-13 | us-east-1 (北弗吉尼亚) | 未指定 | 影响 Amazon SimpleDB 服务部分关键组件,导致部分用户无法访问或操作数据库。 | 电源问题引发系统中断。 | 较小规模事件,AWS 快速恢复;行业评价为基础设施电源冗余不足的典型案例。 |
| 2014-08-07 | EU West (爱尔兰) | 未指定 | 影响 EC2、EBS 和 RDS 服务,导致部分欧洲用户实例、存储和数据库不可用。 | 内部系统事件,未公布详细根因。 | 区域性事件,影响欧洲客户;评价为 AWS 早期区域隔离不完善的体现。 |
| 2014-11-26 | 全球 (CloudFront DNS) | 约 2 小时 | DNS 服务器宕机,影响 CDN 服务,导致部分网站和云服务离线,无法解析请求。 | DNS 服务器故障。 | 短暂但广泛影响;行业称其为“世界上最大云的 DNS 脆弱性暴露”。 |
| 2015-09-20 | us-east-1 (北弗吉尼亚) | 数小时 | DynamoDB 故障导致内部服务通信中断,波及 Netflix、Reddit、IMDb 和 Amazon 自身站点,用户无法访问视频、社交和电商服务。 | 内部多个服务通信中断,引发连锁反应。 | 严重事件,影响数百万用户;评价为 AWS 内部依赖性过高的警示。 |
| 2017-02-28 | us-east-1 (北弗吉尼亚) | 4-5 小时 | S3 控制平面瘫痪,影响 Slack、Trello、GitHub Pages、Quora 等大量网站,无法加载图像和文件。 | 工程师误删关键配置(打字错误)。 | 历史上最著名故障之一,称为“最贵的一次 typo”;行业评价强调人为错误风险。 |
| 2020-11-25 | us-east-1 (北弗吉尼亚) | 数小时 | Kinesis 和 Cognito 故障,影响 Roku、Adobe、Flickr 等企业客户,流媒体和认证服务中断。 | 容量更新问题引发中断。 | 疫情期间事件,影响远程工作;评价为容量管理挑战。 |
| 2022-12-05 | us-east-2 (俄亥俄) | 约 40 分钟 | 可用区中断,影响区域内多项服务,导致部分客户资源不可用。 | 未公布详细根因,可能是网络或电源问题。 | 短暂事件,但凸显可用区依赖;行业建议多 AZ 架构。 |
| 2023-06-13 | us-east-1 (北弗吉尼亚) | 未指定 | Lambda 服务事件,广泛影响大型组织如 Boston Globe、纽约地铁和 Associated Press,无法执行无服务器函数。 | 未公布详细根因。 | 区域性大范围中断;评价为无服务器计算脆弱性暴露。 |
| 2024-07-30 | us-east-1 (北弗吉尼亚) | 未指定 | Kinesis Data Streams 故障,导致依赖服务连锁中断,影响实时数据处理应用。 | 未公布详细根因,可能是内部系统问题。 | 影响数据流服务;行业评价为流处理依赖风险。 |
| 2025-02 | eu-north-1 (斯德哥尔摩) | 未指定 | 网络故障影响一个 AZ 内多项核心服务,导致欧洲部分用户中断。 | 重大网络故障。 | 区域性事件;评价为欧洲基础设施扩展挑战。 |
| 2025-10-19/20 | us-east-1 (北弗吉尼亚) | 约 15 小时以上 | DynamoDB API 端点中断,影响 Slack、Atlassian、Snapchat、Reddit、Roblox、Fortnite、Coinbase、Venmo、Duolingo、Canva、PlayStation Network、银行、航空公司(如 Delta、United 航班延误)和 Amazon 服务;超 3500 家公司、60+ 国家受影响,用户报告超 1700 万次。 | DNS 解析故障引发连锁反应。 | 2025 年最大故障,称为“云脆弱性大暴露”;行业评价为 DNS 和控制平面依赖的重大教训,强调多云策略。 |
分析比较严重的事故
在 2014-2025 年间,AWS 经历了多次故障,其中最严重的几起包括 2015-09-20 的 DynamoDB 故障、2017-02-28 的 S3 故障,以及 2025-10-19/20 的 DynamoDB DNS 故障。这些事件均发生在 us-east-1 区域,该区域作为 AWS 最古老和最繁忙的中心,常因内部依赖和规模效应成为故障高发地。
- 严重程度比较:
- 2015 DynamoDB 故障:持续数小时,影响 Netflix、Reddit 等娱乐和社交平台,导致用户无法访问内容。后果主要是娱乐中断,但未波及金融或交通。根因是内部通信失败,暴露了服务间连锁风险。行业评价为 AWS 早期架构依赖的典型问题,推动了后续的多区域冗余改进。
- 2017 S3 故障:持续 4-5 小时,由人为错误(打字错误)引发,影响 Slack、Trello 等生产力工具和数百万网站的文件托管。经济损失巨大,估计数亿美元。相比 2015 年,此次更强调人为因素,促使 AWS 加强自动化和错误检查机制。
- 2025 DynamoDB DNS 故障:持续 15+ 小时,是三者中最长,影响范围最广,波及 3500+ 公司,包括金融(Coinbase、Venmo)、游戏(Fortnite、Roblox)、教育(Duolingo)和交通(航空延误)。用户报告超 1700 万次,全球 60+ 国家中断。根因是 DNS 解析问题,凸显控制平面脆弱性。相比前两次,此次后果更严重,涉及关键基础设施,行业评价为“云时代最大中断”,呼吁企业采用多云或混合云策略以分散风险。
总体而言,这些严重故障的共同点是 us-east-1 的中心化问题和连锁反应,严重度随时间推移而增加(从数小时到 15+ 小时,从娱乐到关键服务),反映了互联网对云依赖的加深。AWS 通过 PES 报告持续改进,但行业建议企业避免单区域依赖,实现真正的高可用架构。
阿里云的故障
阿里云自2014年至2025年期间,公开报道和官方披露的真正影响面广、持续时间长、被广泛称为“重大事故”的故障并不算特别多(相比体量来说,整体SLA表现仍属行业前列),但其中几次确实造成了较大社会影响和行业讨论。下面按时间顺序列出公认的几次重大级别故障(主要基于公开信息、官方公告、媒体和社区复盘):
| 时间 | 地域/范围 | 持续时长 | 主要影响范围与后果 | 官方/主流原因说明 | 备注 / 行业评价 |
|---|---|---|---|---|---|
| 2018年6月 | 部分地域(具体未公开细节) | 约30分钟 | 部分云产品出现异常,影响范围相对有限 | 未详细公开 | 当时被部分媒体称为“重大技术故障” |
| 2019年3月3日 | 华北2(北京)可用区C | 数小时 | 大量ECS实例磁盘故障,众多网站/App瘫痪 | 磁盘故障 | 当时影响较大,阿里云按SLA赔付 |
| 2022年12月18日 | 香港Region 可用区C | 约15.5小时 | 香港区几乎全地域服务中断,澳门多家关键机构网站(金融管理局、银河、莲花卫视等)不可用,OKX交易受影响 | 制冷设备故障 → 连锁反应导致大面积宕机 | 被广泛称为“阿里云发展史上最严重丑闻之一” |
| 2023年11月12日 | 全球所有地域、所有服务 | 约3小时16分钟 | 控制台、API、MQ、微服务、监控、机器学习等几乎全线产品异常;淘宝、钉钉、闲鱼、饿了么、阿里云盘等集体“崩” | 底层核心组件(鉴权/元数据/控制面组件)故障 | 公认阿里云史上最严重、影响范围最广的一次,被称为“史诗级”“行业闻所未闻” |
| 2023年11月27日 | 部分服务器 | 近2小时 | 服务器访问异常 | 未详细披露 | 距离11·12事故仅半个月,再次引发信任质疑 |
| 2024年7月2日 | 部分地域/服务 | 数小时 | 控制台及部分服务异常 | 未见详细复盘 | 属于中型故障,影响面小于前几次 |
| 2025年(具体日期不详) | 全球范围(疑似域名相关) | 约6小时 | 域名劫持导致全球服务异常 | 域名劫持相关 | 来自2025年公有云故障汇总报告,细节待确认 |
重要说明与趋势观察
-
2014–2018早期:这个阶段阿里云对外公开的重大P0级故障记录极少,更多是局部、小范围问题。那时体量远小于现在,故障影响面也较小。
- 最严重的两次:
- 2022.12香港区15.5小时 → 单地域最长时间故障,对港澳地区关键基础设施影响恶劣。
- 2023.11.12全球3小时+ → 控制面/全局服务全部瘫痪,被公认为云计算历史上罕见的“全地域×全服务”同时故障,打破了阿里云长期标榜的“多活、多中心、N个9”神话。
-
2024–2025:从已知信息看,故障频次和严重程度相比2022–2023有所下降,但仍然偶有中大型事件(尤其是2025年的域名劫持类事件影响面较广)。
- 阿里云的处理特点:
- 大部分重大故障后都会发详细复盘说明(尤其是2022香港、2023全球两次)
- 按SLA赔付(通常是故障时长对应倍数的代金券)
- 高管/官方会公开致歉
总体而言,阿里云在2014–2025这十二年间真正称得上“重大事故”的次数大约在5–7次左右,其中2023年11月12日和2022年12月香港是公认的影响力和严重程度最高的两起。
谷歌云的故障
谷歌云(Google Cloud Platform,简称GCP)从2014年到2025年这段时间内,整体SLA表现相对较好,真正影响全球范围或多个核心服务的重大事故并不算特别频繁(比AWS和Azure略少一些全局性灾难级事件)。但一旦出问题,通常会波及大量第三方应用(如Snapchat、Spotify、Discord、Cloudflare依赖的服务等),社会影响较大。
下面按时间顺序列出公认的比较严重的、影响面广的GCP重大故障(基于公开Status Dashboard、媒体报道、Wikipedia、行业复盘等信息):
| 时间 | 地域/范围 | 持续时长 | 主要影响范围与后果 | 主流原因说明 | 备注 / 行业评价 |
|---|---|---|---|---|---|
| 2015年8月 | 欧洲(比利时Ghlin) | 数小时 | Compute Engine 读写错误率极高,少量数据丢失 | 雷击导致数据中心部分设备损坏 | 谷歌罕见承认数据丢失,影响较小客户群 |
| 2018年7月 | 全球(多地域) | 数小时 | GCP多服务异常,Snapchat、Spotify等第三方应用大面积无法登录/使用 | 网络拥塞 + 内部路由问题 | 当时被广泛报道,第三方影响很明显 |
| 2019年6月2日 | 美国东部 + 全球波及 | 约4–5小时 | YouTube、Gmail、G Suite大面积不可用,Snapchat、Discord、Vimeo等登录失败 | 美国东部网络拥塞 + 级联故障 | 影响范围广,社交媒体热议 |
| 2020年12月14日 | 全球 | 约1小时 | Gmail、YouTube、Google Home、Nest、Pokémon GO等几乎所有依赖身份验证的服务瘫痪 | 身份认证系统(类似IAM)全局故障 | 谷歌消费级服务集体“崩”,影响最大的一次之一 |
| 2022年8月 | 美国爱荷华州数据中心 | 局部影响 | 电气火灾(3人受伤),部分服务受波及,但非全局 | 数据中心电气事故引发火灾 | 更多是物理设施事故,非纯软件/架构问题 |
| 2023年4月 | 欧洲(巴黎等) | 数小时 | 多地域网络 + 服务中断,部分客户受影响 | 洪水 + 数据中心问题 + 网络故障组合 | 天气因素导致,影响面中等 |
| 2024年10月23日 | 欧洲(德国法兰克福 europe-west3) | 约半天(12+小时) | 该地域几乎全服务不可用,影响大量欧洲客户 | 未详细公开(疑似控制面/网络问题) | 单地域最长时长故障之一 |
| 2025年6月12日 | 全球(多地域,40+个) | 约2.5–3小时 | 70+项GCP服务异常,IAM身份授权系统崩溃,导致API请求全面失败;Spotify、Discord、Twitch、Cloudflare、Fitbit、Gmail、Drive、YouTube等大面积瘫痪 | Service Control(API鉴权核心组件)自动化更新引入严重bug → 崩溃循环 → 全局过载 | 公认2020年后GCP最严重的一次全局故障,影响互联网大片区域 |
| 2025年7月18日 | us-east1 | 约2小时 | 多产品错误率升高 | 未详细披露 | 中型故障,恢复较快 |
Azure的故障
Microsoft Azure(微软云平台)从2014年到2025年这段时间内,真正影响面广、持续时间长、社会关注度高的重大事故数量不算特别多(相比早期体量较小时的频繁小故障已显著减少),但几次事件确实造成了全球性或多服务级别的严重影响,尤其涉及Microsoft 365、Teams、Xbox、Outlook等消费级/企业级产品时,传播效应非常明显。
下面按时间顺序列出公认的重大级别故障(基于Azure官方Status History、Post Incident Reviews、媒体报道、Wikipedia和行业复盘等公开信息):
| 时间 | 地域/范围 | 持续时长 | 主要影响范围与后果 | 主流原因说明 | 备注 / 行业评价 |
|---|---|---|---|---|---|
| 2014年8月14–18日 | US Central、US East、US East 2、Europe North | 多日多次,单次数小时 | Cloud Services、SQL Database、VM、Websites、HDInsight、Mobile Services、Service Bus等大面积不可用 | 多起网络/存储问题叠加 | 2014年最集中的一波故障,当时Azure还较年轻 |
| 2014年11月18–19日 | 多地域(美、欧、亚部分) | 约11小时 | Azure Storage为核心,引发VM、Websites、Visual Studio Online、Xbox Live、MSN、Search等20+服务中断 | 存储性能优化配置变更导致Blob前端无限循环 | Azure早期最严重的一次,官方详细RCA,赔付客户 |
| 2016年9月15日 | 全球 | 数小时 | DNS解析大面积故障,影响大量依赖Azure DNS的服务 | 全球DNS问题 | 暴露DNS单点风险 |
| 2018年6月20日 | 北美多个数据中心 | 数小时–1天+ | 冷却系统故障(雷击+浪涌保护不足)导致多服务中断 | 物理设施问题(雷击引发连锁反应) | 罕见的硬件+基础设施类大故障 |
| 2018年9月4日 | 多地域 | 超过25小时(部分服务3天) | 多项核心服务长时间不可用 | 冷却系统故障(雷击+浪涌保护不足) | 恢复时间最长的一次之一 |
| 2023年1月23日 | 全球(核心网络受影响) | 约3小时 | Microsoft 365(Teams、Outlook、Exchange)、部分Azure服务中断 | 广域网(WAN)问题 | M365集体“崩”,影响巨大 |
| 2024年7月18日 | US Central | 约半天 | Virtual Machines等服务管理操作失败,客户无法访问托管服务 | 访问控制错误 + 基础设施故障 | 与次日CrowdStrike全球蓝屏事件时间接近,但独立 |
| 2025年1月8–9日 | East US 2 等 | 数小时 | Azure Databricks、Synapse、Functions、App Service、VM等网络中断 | 网络组件问题 | 2025年初较显著的一次 |
| 2025年10月29日 | 全球 | 约8小时 | Azure Front Door为核心,引发Microsoft 365、Outlook、Teams、Xbox Live、Minecraft、Copilot大面积瘫痪;第三方如Alaska Airlines、Heathrow机场、Costco、Starbucks等受波及 | Azure Front Door配置变更 + 防护机制bug导致配置不一致全局传播 | 2025年Azure最严重的一次,Downdetector超3万报告,类似AWS同月故障 |
| 2025年11月5–6日 | West Europe (AZ01) | 约9–10小时 | VM、PostgreSQL/MySQL Flexible Server、AKS、Storage、Service Bus等多服务降级/中断 | 数据中心热事件(Thermal event) | 区域级较严重故障 |
重要观察与趋势(2014–2025)
- 2014年:Azure还处于快速扩张期,配置变更和存储层问题频发,是故障最集中的一年(尤其是11月那次被视为经典案例)。
- 2015–2019:故障频率下降,但仍以单地域或基础设施(冷却、雷击、DNS)为主,影响面相对可控。
- 2020–2023:重大全局故障较少,更多是网络或M365依赖Azure导致的间接影响(如2023年1月)。
- 2024–2025:控制面/边缘服务(如Azure Front Door)成为新痛点,2025年10月29日事件被公认为近几年Azure最严重的全球性中断,影响范围堪比阿里云2023年11月或谷歌云2025年6月的事件。
- 典型特点:
- 微软每次重大事故后都会发布详细Post Incident Review (PIR)(官方复盘),透明度较高。
- 经常因配置变更、控制平面组件、网络问题引发(而非底层硬件故障)。
- 第三方传播效应极强:一旦M365、Xbox、Teams出问题,社会关注度瞬间拉满。
- 按SLA赔付(信用额度形式),但客户更在意业务连续性。
总体而言,Azure在2014–2025这12年间真正达到重大级别(全球/多服务长时间中断)的故障大约8–10次,严重程度和频率与AWS、GCP处于同一量级,但配置错误导致的级联故障是Azure历史上反复出现的模式。
Cloudflare的故障
Cloudflare(Cloudflare)作为全球最大的CDN、安全、DNS和边缘计算提供商之一,从2014年到2025年期间,真正影响面广、造成互联网大面积瘫痪的重大事故并不算特别多,但一旦发生,通常会波及数百万到数亿用户,影响范围极广(因为Cloudflare承载了全球约20–25%的网页流量)。
Cloudflare的故障特点是:恢复速度通常较快(大部分在1–4小时内缓解),但传播效应极强——一旦核心代理层、DNS或安全组件出问题,很多顶级网站(X、ChatGPT、Shopify、Discord、Spotify、AWS部分服务等)会同时出现5xx错误或无法访问。
下面按时间顺序列出公认的重大级别故障(基于Cloudflare官方博客、status.cloudflare.com历史、媒体报道、Wikipedia和行业复盘,重点筛选全球/核心流量中断事件):
| 时间 | 范围 | 持续时长 | 主要影响范围与后果 | 主流原因说明 | 备注 / 行业评价 |
|---|---|---|---|---|---|
| 2019年7月2日 | 全球 | 约1–2小时 | 大量网站出现502/503/504错误,互联网大片区域无法访问 | 软件部署引入严重bug,导致代理层崩溃 | Cloudflare公认史上最严重的一次,官方详细复盘 |
| 2020年多次 | 部分地域/控制面 | 数小时 | 仪表盘、分析、部分API不可用;核心代理层基本稳定 | 控制平面组件问题 | 影响开发者较多,普通用户感知较小 |
| 2022年6月 | 多数据中心(19个) | 约1.5小时 | 核心代理层中断,多个网站无法访问 | 网络配置错误 | 中等规模,恢复较快 |
| 2025年3月21日 | 全球 | 约1小时7分钟 | 存储读写严重故障,影响大量依赖Cloudflare存储/缓存的服务 | KV/存储层写失败 + 部分读异常 | 2025年早期较显著的一次 |
| 2025年6月12日 | 全球(部分新功能) | 数小时 | 部分新功能/服务不可用,核心流量基本正常 | 特定模块部署问题 | 非核心流量中断,影响有限 |
| 2025年7月14日 | 全球(1.1.1.1 DNS) | 约62分钟 | 公共DNS解析器(1.1.1.1)完全不可用,大量用户无法上网 | 配置错误导致BGP路由撤回,DNS前缀从全球路由表消失 | 对依赖1.1.1.1的用户影响极大,堪称“断网级” |
| 2025年10月左右 | 部分服务 | 数十到几十分钟 | DNS解析短暂中断 | DNS相关配置问题 | 中型故障 |
| 2025年11月18日 | 全球 | 约4–5小时(高峰期更长) | 大规模互联网中断:X(Twitter)、ChatGPT、Shopify、Spotify、Letterboxd、Indeed、Canva、Uber、DoorDash、Truth Social、League of Legends等大量顶级服务瘫痪;约20%网页流量受影响,1/3 Alexa前1万网站受波及 | Bot Management特征文件异常膨胀(数据库权限变更导致文件大小翻倍)→ 全网传播 → 代理层崩溃 | 2025年最严重的一次,也是2019年后Cloudflare最严重的全局流量中断 |
| 2025年12月5日 | 全球 | 数小时 | 再次出现大范围5xx错误,Shopify、Zoom、Vinted、Fortnite、Square、Just Eat、Canva、Vimeo、AWS部分服务、Deliveroo等受影响 | 未见完整官方根因(疑似配置/传播类问题) | 距离11月18日仅17天,连续两次重大事故引发强烈质疑 |
重要观察与趋势(2014–2025)
- 2014–2018早期:Cloudflare体量快速增长,但公开的全局重大故障记录很少,主要是一些局部、地域性或功能性问题。那时互联网对Cloudflare的依赖度远低于现在。
- 2019年7月:成为Cloudflare历史上最经典的“黑天鹅”事件,此后6年多时间里再未出现同等规模的核心代理层全局中断。
- 2025年成为异常年份:
- 出现了至少3–4次影响面较大的全球/近全球事件(尤其是11月18日和12月5日连续两次)。
- 11月18日 被公认为2019年后最严重的一次,影响范围和深度都极高。
- 12月5日再次中断,让很多人质疑Cloudflare的变更控制、回滚机制和“fail small”原则执行情况。
- 典型特点:
- 大部分严重故障都与配置变更、特征文件/规则传播、控制面组件或DNS/BGP相关。
- 官方复盘非常透明:每次重大事故后都会在blog.cloudflare.com发布详细post-mortem(根因、时间线、改进措施)。
- 恢复速度通常较快(回滚 + 停止传播),但影响传播极广(因为Cloudflare的Anycast网络和安全挑战机制)。
- 不像AWS/Azure/Google那样有明确的SLA信用赔付,但会提供详细解释和改进承诺。
总体而言,Cloudflare在2014–2025这12年间真正达到重大级别(全球核心流量长时间中断)的故障大约5–7次,其中2019年7月和2025年11月18日是公认的两个峰值事件。2025年故障频次明显上升,引发了行业对“互联网基础设施集中化风险”的新一轮讨论。
腾讯云的故障
腾讯云(Tencent Cloud)从2014年到2025年期间,作为中国第二大公有云厂商(仅次于阿里云),整体稳定性在国内云厂商中属于中上水平,真正影响面极广、持续时间长、社会关注度高的全局/多地域重大事故数量相对较少,但一旦出现控制面(管控台/API)或核心存储问题,影响会迅速放大到大量企业和开发者。
腾讯云的status页面(https://status.cloud.tencent.com/history)公开透明度相对较低,历史事件列表通常只展示最近1年,且很多中大型故障不会出现在公开列表中,主要靠官方微信公众号、技术博客、媒体报道和社区讨论拼凑完整图景。
下面按时间顺序列出公认的比较严重的、影响面较广的腾讯云故障事件(基于官方复盘、媒体报道、知乎/微博/开发者社区讨论等公开信息):
| 时间 | 地域/范围 | 持续时长 | 主要影响范围与后果 | 主流原因说明 | 备注 / 行业评价 |
|---|---|---|---|---|---|
| 2014年11月2日 | 全国(管控面+部分服务) | 约6分钟 | 腾讯云官网访问慢、图片加载失败、控制台异常,部分用户无法正常使用 | 未详细公开(疑似网络/负载问题) | 早期小体量时期,影响有限,但被当时媒体广泛报道 |
| 2018年8月 | 部分用户/云硬盘 | 不确定(单用户影响数小时至永久) | 多位用户云服务器磁盘数据清零/丢失,涉及千万元级别损失 | 磁盘静默错误 + 数据迁移过程中校验/副本机制失效 | 腾讯云历史上最严重的“丢数据”事件,引发云安全信任危机,官方发详细复盘 |
| 2023年(零星报道) | 部分地域/服务 | 数十分钟–数小时 | 零星控制台/API异常、存储访问抖动 | 未见公开详细复盘 | 相比阿里云同年11月全球事故,腾讯云这一年相对平稳 |
| 2024年4月8日 | 全球17个地域 | 约74–87分钟 | 控制台完全无法登录、云API全面报错(504 Gateway Timeout)、CVM/RDS等实例正常运行但无法管理/续费/扩容等操作;1957个客户报障 | 云API新版本向前兼容性不足 + 配置数据灰度机制缺失 → 全量发布导致全局传播 | 腾讯云近年来最严重的一次,被广泛称为“全球大故障”“管控面崩盘”,类似阿里云2023年11月风格 |
| 2025年10月15日 | 多地域 | 约数十分钟–1小时 | 弹性伸缩(Auto Scaling)等服务异常 | 未详细公开 | 来自status页面,属于中型故障 |
| 2025年10月17日 | 广州地域 | 约1小时多 | 智能数智人相关服务异常 | 未详细公开 | 区域级,影响特定AI/数字人产品 |
重要观察与趋势(2014–2025)
- 早期(2014–2018):故障多为存储层数据丢失或短时访问异常,典型如2018年“丢数据”事件对企业信任打击最大。
- 2019–2023:腾讯云故障频次和严重度明显下降,鲜有全国/全球级事件,稳定性优于阿里云同期(尤其是2023年阿里云11·12史诗级故障时腾讯云表现平稳)。
- 2024–2025:2024年4月8日成为转折点,这次管控面全局故障让很多人重新审视腾讯云的“变更安全”和“灰度发布”能力。2025年出现几次中型事件,但未见类似2024年4月或阿里云/谷歌云那种“全服务瘫痪”级别。
- 典型特点:
- 控制面/API问题是近年最主要痛点(2024年4月事件典型代表)。
- 存储/数据丢失类事故对企业杀伤力最大(2018年案例)。
- 腾讯云官方复盘相对及时(尤其是重大事件会在公众号、技术社区发详细说明)。
- 没有像AWS/Azure/Google那样严格的SLA信用赔付机制,但会提供代金券/补偿。
- 故障传播效应不如阿里云、Cloudflare那么剧烈(因为腾讯云客户结构更偏企业/游戏/视频,对消费互联网依赖相对低)。
总体而言,腾讯云在2014–2025这12年间真正称得上重大级别(全国/全球管控面长时间不可用或严重数据丢失)的故障大约3–5次,其中2018年丢数据和2024年4月8日全球管控面故障是公认影响力和讨论度最高的两起。
故障透明度
就故障透明度而言,阿里云和腾讯云是比较薄弱的。 阿里云的健康看板(https://status.aliyun.com/#/?region=cn-shanghai)和腾讯云的健康看板(https://status.cloud.tencent.com/history)只显示了过去1年发生过的历史事件。
Azure(https://azure.status.microsoft/en-us/status/history/)保留了5年,cloudflare(https://www.cloudflarestatus.com/history?page=17)最详细透明,可以使用page一直翻页到前面几年的事故。
公有云“死因”
在我年轻的时候,我热衷于查阅并重构别人的代码。直到Java Boy给了我上了一课: 即便我帮他修复了内存泄露的问题,他感受到的是一种来自内心深处的存在主义危机。他以愤怒作为掩盖自己无能的藉口,把“维持kubernetes平台稳定”的罪责推到我身上。
其实我也不是很乐意帮他擦屁股。我只是觉得频繁出现的OOM kill event 报警让我很烦躁而已。从这个故事中,我领悟了0的哲学:边际收益为0的重构没人愿意做。
因此便能推导得出软件行业的熵增定律:项目代码库会随着时间推移而变成一座屎山。
有人问,这跟公有云的死因有什么关系呢?
实际上是非常有关系的。因为“工业克苏鲁”要求企业贡献随时间递增的利润。因此对于公有云厂商,对于他们的基层员工而言,就必须“讲一种新的增长故事”,比如现在是2026年,就以AI作为新的增长极。
而旧的的代码就一直烂在那里。因为修改他们没有任何边际收益。
于是大家就逐渐形成这种共识:不修改别人的代码,任由它成为一座屎山。代码如此,架构亦如此。即便网络拓扑成为纯粹的相互依赖的网状结构,反正出事的时候大家都用不了,当宕机责任被平等分摊,自己便没有责任。
讽刺的是,一个在职期间0故障发生,天天上班睡觉的运维工程师,会被认为是一个不称职的人。因为他看起来啥事都没做。然而反直觉的是,这种人其实应该当成企业的吉祥物供起来,因为你根本不知道他之前为了公司的业务稳定付出了多少努力。或者说他纯粹是命好,配享大庙。
实际上,最好的运维在于不运维。因为运维收入与职业风险完全不对等。上级不会因为你删除了一个看起来没用的配置,而在这个月多给你发一笔补贴;但你会因为删除了一个有用的数据库配置,而遭到客户的辱骂。
公有云企业忘了,网络效应可以把他们扶起来,也可以把他们重重地摔下去。当他们的客户越多,单次宕机而产生的网络连锁反应就会越大。就好比2025年12月4日晚约21:00–23:37的支付宝故障,这已经是阿里系在2025年的第六次大故障。
当用户规模以亿作为计算单位,每一秒都有人在支付。然而业务又要求往软件上继续加新的功能,最后整个系统不堪重负。
而且公有云服务厂商赔付完全不对等。像支付宝这种最多就是多退少补,少收用户的钱当做福利。但政企的损失则完全无法估算。如果业务寄宿在公有云上,而公有云宕机了,那么作为业务方的你,要怎么向公有云介绍自己的损失呢?
“我的系统每天交易几百个亿,你赔我几个亿?”
客户的损失无法量化,因此阿里云通常都是赔点代金券。但这完全是杯水车薪。损失的时间,谁也无法说清楚实际的业务影响和时间价值。
网络效应带来了公有云指数级别的收入增长。但作为大型政企用户而言,对公有云反依赖应该提上日程。把自己的命运跟单一的云厂商绑定,无法应对突发的风险。
小并发高可用系统
在此基础上,我提出我的“小并发高可用系统”概念。我的初步设想是通过存储的冗余,实现业务的高可用。 当流量平稳分摊到设计冗余的信息系统,既规避了集中式流量带来的单集群流量洪峰,又减少了问题扩散的半径。
举个最简单的例子。在DNS解析的时候,把广东的DNS解析设置在一个华南区域的阿里云、腾讯云kubernetes集群。每一个集群互不依赖,运行内部完整的信息业务系统。 这样最坏情况,公有云自身出问题,只会出现50%的不可用。
同时不可用,概率极小。
孤帆远影碧山尽,唯见长江天际流
参考链接
【1】 2025 年 11 月 18 日 Cloudflare 服务中断 https://blog.cloudflare.com/zh-cn/18-november-2025-outage/
【2】 从 AWS 故障看 DNS 的隐形杀伤力:DeepFlow 如何在混乱中快速锁定根因 https://my.oschina.net/u/3681970/blog/18697034
【3】 2023-11-12阿里云故障复盘与分析 https://github.tiankonguse.com/blog/2023/11/29/aliyun-break.html
Summary
This article starts from formal logic and definitions (network effect, law of entropy increase, anti-dependency, and the “zero” philosophy of zero marginal benefit), systematically reviews major outages of mainstream public clouds and infrastructure—Alibaba Cloud, Google Cloud, Azure, Cloudflare, Tencent Cloud—from 2014 to 2025, and compares their fault transparency. On this basis, it analyzes the “causes of death” of public cloud: software entropy and zero marginal benefit make legacy code and architecture hard to govern; network effects amplify cascading failures; and SLA compensation is severely misaligned with actual losses for enterprises and government. The author recommends that large enterprises and government agencies prioritize “anti-dependency” on any single public cloud and proposes a “small-concurrency high-availability system”—reducing single-point risk and blast radius through storage redundancy and traffic distribution (e.g., multi-region, multi-cluster DNS resolution).
Formal Logic and Definitions
Network effect: The more users (or participants) a product/service/platform has, the more valuable it becomes to each user.
Law of entropy increase: A project’s codebase will, over time, turn into a mess.
Anti-dependency: The reverse of depending on a single programming language, tech stack, or cloud platform. Examples: polyglot programming, multi-stack choices, multi-cloud strategy. Anti-dependency lets the business run smoothly without being tied to one language, open-source project, or public cloud.
Zero: Nobody wants to do refactoring whose marginal benefit is zero.
AWS Outages
| Time | Region / Scope | Duration | Main Impact & Consequences | Official / Main Cause | Notes / Industry Evaluation |
|---|---|---|---|---|---|
| 2014-06-13 | us-east-1 (Northern Virginia) | Not specified | Affected key components of Amazon SimpleDB, some users unable to access or operate databases. | Power-related system interruption. | Relatively small-scale; quick recovery; highlighted power redundancy issues. |
| 2014-08-07 | EU West (Ireland) | Not specified | Impacted EC2, EBS, and RDS; some European users lost access to instances, storage, and databases. | Internal system event (root cause not detailed). | Regional impact; showed early limitations in regional isolation. |
| 2014-11-26 | Global (CloudFront DNS) | ~2 hours | DNS servers down, affected CDN; many websites and cloud services failed to resolve requests. | DNS server failure. | Short but broad impact; exposed DNS fragility of the world’s largest cloud. |
| 2015-09-20 | us-east-1 | Several hours | DynamoDB outage caused internal service communication failure; affected Netflix, Reddit, IMDb, Amazon properties. | Internal service communication chain reaction. | Serious incident; millions impacted; warned about tight internal dependencies. |
| 2017-02-28 | us-east-1 | 4–5 hours | S3 control plane outage; Slack, Trello, GitHub Pages, Quora, many sites lost images/files. | Engineer typo deleted critical configuration. | One of the most famous outages ever; “most expensive typo in history”. |
| 2020-11-25 | us-east-1 | Several hours | Kinesis and Cognito disruption; affected Roku, Adobe, Flickr; streaming & auth services down. | Capacity update issue. | Happened during pandemic; highlighted capacity planning challenges. |
| 2022-12-05 | us-east-2 (Ohio) | ~40 minutes | Availability Zone outage; impacted multiple services in the region. | Not publicly detailed (likely network/power). | Short but emphasized importance of multi-AZ architecture. |
| 2023-06-13 | us-east-1 | Not specified | Lambda service disruption; affected large organizations (Boston Globe, NYC subway, AP, etc.). | Not publicly detailed. | Exposed fragility of serverless computing at scale. |
| 2024-07-30 | us-east-1 | Not specified | Kinesis Data Streams outage; impacted real-time data processing applications. | Not publicly detailed. | Highlighted risks in stream-processing dependencies. |
| 2025-02 | eu-north-1 (Stockholm) | Not specified | Major network issue in one AZ; affected core services in Europe. | Major network failure. | Regional event; reflected challenges in European infrastructure expansion. |
| 2025-10-19/20 | us-east-1 | >15 hours | DynamoDB API endpoint outage (DNS failure); impacted Slack, Reddit, Roblox, Fortnite, Coinbase, Venmo, Duolingo, Canva, PlayStation, banks, airlines (Delta/United delays), Amazon services; >3,500 companies, 60+ countries, >17 million user reports. | DNS resolution failure leading to cascading effect. | Largest cloud outage of 2025; called “the biggest cloud fragility exposure”; strongly pushed multi-cloud strategies. |
Analysis of the most severe incidents
The most severe outages were 2015-09-20 (DynamoDB), 2017-02-28 (S3), and especially 2025-10-19/20 (DynamoDB DNS). All occurred in us-east-1, AWS’s oldest and busiest region.
Severity ranking:
- 2015: entertainment & social platforms heavily affected, but limited to consumer services.
- 2017: massive productivity and developer impact; huge economic loss due to human error.
- 2025: longest duration (>15h), broadest scope (finance, gaming, education, aviation, critical infrastructure), highest user impact — widely regarded as the most serious single cloud outage in recent years.
Common lessons: over-reliance on us-east-1, control-plane fragility, cascading failures. Industry increasingly recommends multi-region, multi-cloud, or hybrid architectures.
Alibaba Cloud Outages
From 2014 to 2025, Alibaba Cloud did not have an unusually high number of major incidents that were widely reported, officially disclosed, truly broad in impact, long in duration, and widely called “major outages” (relative to its scale, its overall SLA remains among the best in the industry). A few of them, however, did cause significant social impact and industry debate. Below is a chronological list of major-level outages (based mainly on public reports, official announcements, media and community post-mortems):
| Time | Region/Scope | Duration | Main Impact and Consequences | Official/Main Cause | Notes / Industry View |
|---|---|---|---|---|---|
| June 2018 | Some regions (details not public) | ~30 min | Some cloud products abnormal, limited impact | Not disclosed in detail | Described by some media as “major technical failure” |
| March 3, 2019 | North China 2 (Beijing) AZ-C | Hours | Many ECS disk failures, many sites/Apps down | Disk failure | Significant impact; Alibaba Cloud compensated per SLA |
| Dec 18, 2022 | Hong Kong Region AZ-C | ~15.5 hours | Hong Kong region largely down; key sites in Macau (monetary authority, Galaxy, Lotus TV, etc.) unavailable; OKX affected | Cooling equipment failure → cascade → large outage | Widely called “one of the worst incidents in Alibaba Cloud history” |
| Nov 12, 2023 | All regions and services globally | ~3h 16m | Console, API, MQ, microservices, monitoring, ML, etc. largely abnormal; Taobao, DingTalk, Xianyu, Ele.me, Alibaba Cloud Drive, etc. down | Core component failure (auth/metadata/control plane) | Widely seen as Alibaba Cloud’s worst, broadest outage; “epic,” “unprecedented in the industry” |
| Nov 27, 2023 | Some servers | ~2 hours | Server access abnormal | Not disclosed in detail | Only half a month after 11·12; renewed trust concerns |
| July 2, 2024 | Some regions/services | Hours | Console and some services abnormal | No detailed post-mortem | Mid-sized; impact smaller than earlier incidents |
| 2025 (date unclear) | Global (suspected DNS-related) | ~6 hours | DNS hijacking led to global service issues | DNS hijacking | From 2025 public cloud outage summary; details TBD |
Important Notes and Trends
-
2014–2018 early: Very few publicly disclosed major P0-level incidents in this period; more local, limited issues. Scale was much smaller; impact was smaller too.
- Two most severe:
- 2022.12 Hong Kong 15.5h → Longest single-region outage; severe impact on critical infrastructure in Hong Kong and Macau.
- 2023.11.12 global 3h+ → Control plane and global services down; widely seen as a rare “all regions × all services” failure, breaking the “multi-active, multi-center, N nines” myth.
-
2024–2025: From known information, frequency and severity are lower than 2022–2023, but medium-to-large events still occur (e.g. 2025 DNS hijacking had broad impact).
- Alibaba Cloud’s handling: Most major incidents get detailed post-mortems (especially 2022 Hong Kong and 2023 global); SLA compensation (usually vouchers); senior/formal apologies.
Overall, in 2014–2025 Alibaba Cloud had roughly 5–7 incidents that qualify as “major,” with Nov 12, 2023 and Dec 2022 Hong Kong generally seen as the two most severe.
Google Cloud Outages
Google Cloud Platform (GCP) had relatively good overall SLA from 2014 to 2025; major incidents that truly affected global scope or multiple core services were not especially frequent (fewer than AWS and Azure in terms of global disasters). When they did occur, they often affected many third-party apps (e.g. Snapchat, Spotify, Discord, services depending on Cloudflare), with high social impact.
Below is a chronological list of serious, broad-impact GCP outages (based on public Status Dashboard, media, Wikipedia, industry post-mortems):
| Time | Region/Scope | Duration | Main Impact and Consequences | Main Cause | Notes / Industry View |
|---|---|---|---|---|---|
| Aug 2015 | Europe (Ghlin, Belgium) | Hours | Compute Engine very high read/write error rate; some data loss | Lightning damaged part of datacenter | Google rarely admitted data loss; limited customer set |
| July 2018 | Global (multiple regions) | Hours | GCP services abnormal; Snapchat, Spotify, etc. largely unusable | Network congestion + internal routing | Widely reported; strong third-party impact |
| June 2, 2019 | US East + global | ~4–5 hours | YouTube, Gmail, G Suite largely down; Snapchat, Discord, Vimeo login failures | US East network congestion + cascade | Broad impact; social media buzz |
| Dec 14, 2020 | Global | ~1 hour | Gmail, YouTube, Google Home, Nest, Pokémon GO, etc.—almost all auth-dependent services down | Identity/auth system (IAM-like) global failure | Consumer services “down”; one of the worst |
| Aug 2022 | Iowa datacenter | Local | Electrical fire (3 injured); some services affected, not global | Datacenter electrical fire | Physical facility; not purely software/architecture |
| Apr 2023 | Europe (Paris, etc.) | Hours | Multi-region network + service disruption | Flood + datacenter + network issues | Weather-related; medium impact |
| Oct 23, 2024 | Europe (Frankfurt europe-west3) | ~12+ hours | Region largely unavailable; many European customers affected | Not disclosed in detail (suspected control plane/network) | One of the longest single-region outages |
| June 12, 2025 | Global (40+ regions) | ~2.5–3 hours | 70+ GCP services abnormal; IAM down → API requests failing; Spotify, Discord, Twitch, Cloudflare, Fitbit, Gmail, Drive, YouTube, etc. down | Service Control (API auth core) automation update introduced severe bug → crash loop → global overload | Widely seen as GCP’s worst global outage since 2020 |
| July 18, 2025 | us-east1 | ~2 hours | Multiple products higher error rates | Not disclosed in detail | Mid-sized; recovery relatively fast |
Azure Outages
Microsoft Azure did not have an unusually high number of major incidents that were broad in impact, long in duration, and highly visible from 2014 to 2025 (compared with earlier, smaller-scale frequent glitches, the trend improved). A few events did cause global or multi-service impact, especially when Microsoft 365, Teams, Xbox, Outlook and other consumer/enterprise products were involved; the propagation effect was very visible.
Below is a chronological list of major-level Azure outages (based on Azure Status History, Post Incident Reviews, media, Wikipedia, industry post-mortems):
| Time | Region/Scope | Duration | Main Impact and Consequences | Main Cause | Notes / Industry View |
|---|---|---|---|---|---|
| Aug 14–18, 2014 | US Central, US East, US East 2, Europe North | Multiple days, hours per event | Cloud Services, SQL Database, VM, Websites, HDInsight, Mobile Services, Service Bus largely unavailable | Multiple network/storage issues | 2014’s most concentrated wave; Azure still young |
| Nov 18–19, 2014 | Multiple regions (US, EU, Asia) | ~11 hours | Azure Storage at core; VM, Websites, Visual Studio Online, Xbox Live, MSN, Search, 20+ services down | Storage perf config change → Blob front-end infinite loop | Azure’s worst early incident; detailed RCA; customer compensation |
| Sep 15, 2016 | Global | Hours | Widespread DNS resolution failure; many Azure DNS–dependent services affected | Global DNS issue | Exposed DNS single-point risk |
| June 20, 2018 | North America multiple datacenters | Hours–1+ day | Cooling failure (lightning + surge protection) → multi-service disruption | Physical facility (lightning cascade) | Rare hardware/infrastructure incident |
| Sep 4, 2018 | Multiple regions | 25+ hours (some services 3 days) | Core services long unavailable | Cooling (lightning + surge) | One of the longest recoveries |
| Jan 23, 2023 | Global (core network) | ~3 hours | Microsoft 365 (Teams, Outlook, Exchange), some Azure services down | WAN issue | M365 “down”; huge impact |
| July 18, 2024 | US Central | ~Half day | VM and other management operations failing; customers unable to access managed services | Access control error + infrastructure failure | Close in time to next-day CrowdStrike global BSOD but independent |
| Jan 8–9, 2025 | East US 2, etc. | Hours | Azure Databricks, Synapse, Functions, App Service, VM network disruption | Network component issue | Notable early 2025 |
| Oct 29, 2025 | Global | ~8 hours | Azure Front Door at core; Microsoft 365, Outlook, Teams, Xbox Live, Minecraft, Copilot down; Alaska Airlines, Heathrow, Costco, Starbucks, etc. affected | Azure Front Door config change + protection bug → inconsistent config propagated globally | 2025’s worst for Azure; Downdetector 30k+ reports; similar to AWS same month |
| Nov 5–6, 2025 | West Europe (AZ01) | ~9–10 hours | VM, PostgreSQL/MySQL Flexible Server, AKS, Storage, Service Bus degraded/out | Datacenter thermal event | Serious regional outage |
Observations and Trends (2014–2025)
- 2014: Azure in rapid expansion; config changes and storage layer issues frequent; most concentrated year (Nov incident is a classic case).
- 2015–2019: Fewer incidents; still mostly single region or infrastructure (cooling, lightning, DNS); impact relatively contained.
- 2020–2023: Few major global outages; more network or M365 dependency on Azure (e.g. Jan 2023).
- 2024–2025: Control plane/edge (e.g. Azure Front Door) became a new pain point; Oct 29, 2025 widely seen as Azure’s worst global outage in recent years, comparable to Alibaba Nov 2023 or GCP June 2025.
- Typical traits: Detailed Post Incident Review (PIR) after major incidents; config change, control plane, network often root causes (not just hardware); strong third-party propagation when M365, Xbox, Teams fail; SLA compensation (credit); customers care most about business continuity.
Overall, Azure had roughly 8–10 major-level (global/multi-service, long) outages in 2014–2025; severity and frequency on par with AWS and GCP; cascading failure from config error is a recurring pattern.
Cloudflare Outages
Cloudflare, as one of the world’s largest CDN, security, DNS, and edge providers, did not have an unusually high number of major incidents that caused broad internet disruption from 2014 to 2025. When they did occur, impact often reached millions to hundreds of millions of users (Cloudflare carries ~20–25% of global web traffic).
Typical pattern: recovery is often fast (most ease within 1–4 hours), but propagation is extreme—when core proxy, DNS, or security components fail, many top sites (X, ChatGPT, Shopify, Discord, Spotify, parts of AWS, etc.) see 5xx or unreachable at once.
Below is a chronological list of major-level Cloudflare outages (based on official blog, status.cloudflare.com history, media, Wikipedia; focused on global/core traffic events):
| Time | Scope | Duration | Main Impact and Consequences | Main Cause | Notes / Industry View |
|---|---|---|---|---|---|
| July 2, 2019 | Global | ~1–2 hours | Many sites 502/503/504; large parts of internet unreachable | Software deploy introduced severe bug → proxy layer crash | Widely seen as Cloudflare’s worst ever; detailed post-mortem |
| 2020 multiple | Some regions/control plane | Hours | Dashboard, analytics, some APIs down; core proxy largely stable | Control plane issues | More impact on developers; less for general users |
| June 2022 | Multiple datacenters (19) | ~1.5 hours | Core proxy down; many sites unreachable | Network config error | Medium scale; fast recovery |
| Mar 21, 2025 | Global | ~1h 7m | Storage read/write severely impaired; many storage/cache–dependent services affected | KV/storage layer write failure + partial read issues | Notable early 2025 |
| June 12, 2025 | Global (some features) | Hours | Some features/services down; core traffic largely OK | Specific module deploy | Not core traffic; limited impact |
| July 14, 2025 | Global (1.1.1.1 DNS) | ~62 minutes | Public DNS resolver (1.1.1.1) fully down; many users unable to reach internet | Config error → BGP route withdrawal → DNS prefix disappeared from global routing table | Severe for 1.1.1.1 users; “internet-breaking” level |
| ~Oct 2025 | Some services | Tens of minutes | Brief DNS resolution disruption | DNS-related config | Mid-sized |
| Nov 18, 2025 | Global | ~4–5 hours (peak longer) | Large-scale internet outage: X (Twitter), ChatGPT, Shopify, Spotify, Letterboxd, Indeed, Canva, Uber, DoorDash, Truth Social, League of Legends, etc.; ~20% web traffic; 1/3 of Alexa top 10k sites | Bot Management rules file abnormal growth (DB permission change → file size doubled) → global propagation → proxy crash | 2025’s worst; also worst global traffic outage since 2019 |
| Dec 5, 2025 | Global | Hours | Widespread 5xx again; Shopify, Zoom, Vinted, Fortnite, Square, Just Eat, Canva, Vimeo, parts of AWS, Deliveroo, etc. | No full official root cause (suspected config/propagation) | Only 17 days after Nov 18; two major incidents in a row raised strong criticism |
Observations and Trends (2014–2025)
- 2014–2018: Cloudflare grew fast; few public global major incidents; more local/regional/functional issues; internet depended on Cloudflare less than today.
- July 2019: Became Cloudflare’s classic “black swan”; no core proxy global outage of similar scale for over six years.
- 2025 as anomaly: At least 3–4 broad global/near-global events (especially Nov 18 and Dec 5 back-to-back). Nov 18 widely seen as worst since 2019. Dec 5 again led many to question change control, rollback, and “fail small.”
- Typical traits: Most serious incidents tied to config change, rules/propagation, control plane, or DNS/BGP; very transparent post-mortems on blog.cloudflare.com; recovery usually fast (rollback + stop propagation), but impact very broad (Anycast + challenge mechanism); no explicit SLA credit like AWS/Azure/Google, but detailed explanation and improvement commitments.
Overall, Cloudflare had roughly 5–7 major-level (global core traffic, long) outages in 2014–2025; July 2019 and Nov 18, 2025 are the two peak events. 2025 saw a clear rise in frequency and renewed discussion of “internet infrastructure centralization risk.”
Tencent Cloud Outages
Tencent Cloud, as China’s second-largest public cloud (after Alibaba Cloud) from 2014 to 2025, had relatively good stability among domestic providers. Truly broad, long, high-visibility global/multi-region major incidents were relatively few; when control plane (console/API) or core storage failed, impact quickly spread to many enterprises and developers.
Tencent Cloud’s status page (https://status.cloud.tencent.com/history) is relatively opaque; history often shows only the last year, and many medium-to-large incidents are missing; the full picture relies on official WeChat, tech blog, media, and community.
Below is a chronological list of serious, broad-impact Tencent Cloud incidents (based on official post-mortems, media, Zhihu/Weibo/developer community):
| Time | Region/Scope | Duration | Main Impact and Consequences | Main Cause | Notes / Industry View |
|---|---|---|---|---|---|
| Nov 2, 2014 | Nationwide (control plane + some services) | ~6 min | Tencent Cloud site slow, images failing, console abnormal; some users unable to use | Not disclosed (suspected network/load) | Early, small scale; limited impact but widely reported |
| Aug 2018 | Some users/cloud disk | Unclear (single-user impact hours to permanent) | Multiple users’ cloud disk data wiped/lost; losses in tens of millions | Silent disk error + migration validation/replica failure | Tencent Cloud’s worst “data loss” incident; trust crisis; detailed post-mortem |
| 2023 (sporadic) | Some regions/services | Tens of min–hours | Sporadic console/API issues, storage jitter | No detailed public post-mortem | Compared with Alibaba Nov 2023 global, Tencent was relatively stable |
| Apr 8, 2024 | 17 regions globally | ~74–87 min | Console fully unreachable; cloud API 504 Gateway Timeout; CVM/RDS instances running but unmanageable/no renew/scale; 1957 customers reported | New API version backward-incompat + missing config gray release → full rollout → global propagation | Tencent Cloud’s most serious in recent years; “global outage,” “control plane collapse”; similar style to Alibaba Nov 2023 |
| Oct 15, 2025 | Multiple regions | ~Tens of min–1 hour | Auto Scaling and other services abnormal | Not disclosed | From status page; mid-sized |
| Oct 17, 2025 | Guangzhou | ~1+ hour | AI digital-human related services abnormal | Not disclosed | Regional; specific AI/digital-human product |
Observations and Trends (2014–2025)
- Early (2014–2018): Failures often storage data loss or short access issues; 2018 “data loss” hit enterprise trust hardest.
- 2019–2023: Tencent Cloud incident frequency and severity dropped; few nationwide/global events; stability better than Alibaba in the same period (e.g. calm during Alibaba 11·12).
- 2024–2025: Apr 8, 2024 was a turning point; control plane global failure led many to reassess “change safety” and “gray release.” 2025 had several mid-sized events but nothing at “full service down” level like Apr 2024 or Alibaba/Google.
- Typical traits: Control plane/API is the main pain point (Apr 2024); storage/data loss is most damaging to enterprises (2018); post-mortems relatively timely (WeChat, tech community); no strict SLA credit like AWS/Azure/Google, but vouchers/compensation; propagation less dramatic than Alibaba/Cloudflare (customer mix more enterprise/gaming/video, less consumer internet).
Overall, Tencent Cloud had roughly 3–5 major-level (nationwide/global control plane long unavailable or serious data loss) incidents in 2014–2025; 2018 data loss and Apr 8, 2024 global control plane are the two most discussed.
Outage Transparency
In terms of outage transparency, Alibaba Cloud and Tencent Cloud are relatively weak.
Alibaba Cloud’s status board (https://status.aliyun.com/#/?region=cn-shanghai) and Tencent Cloud’s (https://status.cloud.tencent.com/history) only show the last year of events.
Azure (https://azure.status.microsoft/en-us/status/history/) keeps five years. Cloudflare (https://www.cloudflarestatus.com/history?page=17) is the most transparent; you can paginate back through earlier years.
“Death” of the Public Cloud
When I was younger, I was keen on reading and refactoring other people’s code. Until “Java Boy” taught me a lesson: even after I fixed his memory leak, what he felt was an existential crisis. He used anger to cover his own inadequacy and blamed “keeping the Kubernetes platform stable” on me.
I wasn’t that eager to clean up his mess either. I just found the frequent OOM kill event alerts annoying. From that story I learned the philosophy of zero: nobody wants to do refactoring whose marginal benefit is zero.
Hence the law of entropy increase in software: a project’s codebase will, over time, turn into a mess.
Someone asked: what does this have to do with the “death” of the public cloud?
It’s very related. Because “industrial Cthulhu” demands that companies deliver ever-increasing profit. So for public cloud vendors and their frontline staff, they must “tell a new growth story”—in 2026, that story is AI.
The old code just rots. Changing it has no marginal benefit.
So everyone converges on the same idea: don’t touch others’ code; let it become a mess. Same for code, same for architecture. Even when the network topology is a pure mesh of mutual dependency, when things break everyone’s down, and when outage responsibility is shared equally, you bear no responsibility.
Ironically, an ops engineer who had zero incidents on their watch and “slept at work” every day would be seen as incompetent—because they look like they did nothing. Counterintuitively, that person should be treated as the company mascot: you have no idea how much they did before to keep things stable. Or they were just lucky and deserve a shrine.
The best ops is no ops. Because ops compensation and career risk are completely misaligned. Your boss won’t give you a bonus for deleting a seemingly useless config; but you will get cursed by customers for deleting a useful database config.
Public cloud vendors forget: network effects can lift them up and can slam them down. The more customers they have, the bigger the network cascade from a single outage. Like the Alipay outage on Dec 4, 2025, ~21:00–23:37—Alibaba’s sixth major incident in 2025.
When user scale is in the hundreds of millions, someone is paying every second. Yet the business keeps asking for more features; eventually the system buckles.
And public cloud compensation is completely misaligned. For something like Alipay it’s at most “refund the difference”; undercharging is treated as a perk. But losses for government and enterprises are incalculable. If your business runs on the public cloud and the cloud goes down, how do you explain your loss to the provider?
“My system does billions in transactions a day; you’re going to compensate me a few hundred million?”
Customer loss is unquantifiable, so Alibaba Cloud usually just hands out vouchers. That’s a drop in the bucket. No one can really account for lost time, actual business impact, or the value of that time.
Network effects brought public cloud exponential revenue growth. For large government and enterprise users, anti-dependency on a single public cloud should be on the agenda. Tying your fate to one cloud vendor cannot handle sudden risk.
Small-Concurrency, High-Availability Systems
On that basis I propose “small-concurrency, high-availability systems”: redundancy in storage to achieve high availability in the business.
When traffic is spread across redundant systems, you avoid the single-cluster traffic spike of centralized flow and shrink the radius of failure.
Simplest example: at DNS resolution, point Guangdong to a South China Alibaba + Tencent Kubernetes cluster. Each cluster is independent and runs a complete internal business system. Worst case, if the public cloud itself fails, you get at most 50% unavailability.
Both being down at once is extremely unlikely.
Farewell, Public Cloud. See you on the Yangtze River.
References
【1】
Cloudflare service outage, November 18, 2025
https://blog.cloudflare.com/zh-cn/18-november-2025-outage/
【2】
The invisible impact of DNS from the AWS outage: how DeepFlow quickly found root cause in chaos
https://my.oschina.net/u/3681970/blog/18697034
【3】
2023-11-12 Alibaba Cloud outage post-mortem and analysis
https://github.tiankonguse.com/blog/2023/11/29/aliyun-break.html
要約
本稿は形式論理と定義(ネットワーク効果、エントロピー増大の法則、反依存性、限界便益ゼロの「ゼロ」の哲学)から出発し、2014年から2025年までのアリババクラウド、Google Cloud、Azure、Cloudflare、テンセントクラウドなど主要パブリッククラウド・インフラの重大障害を体系的に整理し、各社の障害透明性を比較する。その上で、パブリッククラウドの「死因」を分析する:ソフトウェアのエントロピーと限界便益ゼロによりレガシーコード・アーキテクチャの治理が困難になること、障害時にネットワーク効果が連鎖反応を増幅すること、SLA賠償が政企の実際の損失と著しく乖離していること。著者は大型政企が単一パブリッククラウドへの「反依存」を優先すべきだとし、「小並行高可用システム」の構想を提示する——ストレージ冗長とトラフィック分散(例:マルチリージョン・マルチクラスタのDNS解決)により単一点リスクと影響半径を低減する。
形式論理と定義
ネットワーク効果:製品・サービス・プラットフォームの利用者(または参加者)が増えるほど、各利用者にとっての価値が高まる。
エントロピー増大の法則:プロジェクトのコードベースは時間とともにスパゲッティ化する。
反依存性:単一のプログラミング言語・技術スタック・クラウドプラットフォームへの依存の逆。例:多言語混在プログラミング、マルチスタック選定、マルチクラウド戦略。反依存性により、業務は言語・オープンソース・パブリッククラウドに縛られず安定稼働できる。
ゼロ:限界便益がゼロのリファクタリングは誰もやりたがらない。
AWSの障害
| 時期 | 地域 / 範囲 | 継続時間 | 主な影響と結果 | 公式 / 主な原因 | 備考 / 業界評価 |
|---|---|---|---|---|---|
| 2014-06-13 | us-east-1 (北バージニア) | 未詳 | Amazon SimpleDB の重要コンポーネントに影響、一部ユーザーがデータベース操作不可。 | 電源関連の問題 | 小規模、迅速回復;電源冗長性の不足が露呈。 |
| 2014-08-07 | EU West (アイルランド) | 未詳 | EC2、EBS、RDS に影響;欧州の一部ユーザーがインスタンス・ストレージ・DB にアクセス不可。 | 内部システムイベント(詳細非公開) | 地域限定;初期の地域分離の限界を示した。 |
| 2014-11-26 | グローバル (CloudFront DNS) | 約2時間 | DNSサーバーダウン、CDNに影響;多数のウェブサイト・クラウドサービスが名前解決不能。 | DNSサーバー障害 | 短時間だが広範囲;世界最大クラウドのDNS脆弱性が露呈。 |
| 2015-09-20 | us-east-1 | 数時間 | DynamoDB障害→内部通信途絶;Netflix、Reddit、IMDb、Amazon系サービスに広範な影響。 | 内部サービスの連鎖反応 | 深刻なインシデント;数百万ユーザーに影響;内部依存の危険性を警告。 |
| 2017-02-28 | us-east-1 | 4〜5時間 | S3制御平面停止;Slack、Trello、GitHub Pages、Quoraなど多数のサイトで画像・ファイル消失。 | エンジニアの誤操作(重要な設定の誤削除) | 史上最も有名な障害の一つ;「史上最も高価なタイポ」。 |
| 2020-11-25 | us-east-1 | 数時間 | KinesisとCognito障害;Roku、Adobe、Flickrなどに影響;ストリーミング・認証サービス停止。 | キャパシティ更新の問題 | パンデミック中の発生;キャパシティ計画の難しさを浮き彫りに。 |
| 2022-12-05 | us-east-2 (オハイオ) | 約40分 | 可用性ゾーン障害;地域内の複数サービスに影響。 | 詳細非公開(ネットワーク/電源の可能性) | 短時間だがマルチAZの重要性を強調。 |
| 2023-06-13 | us-east-1 | 未詳 | Lambdaサービス障害;Boston Globe、NYC地下鉄、AP通信などに大きな影響。 | 詳細非公開 | サーバーレスコンピューティングの大規模時の脆弱性を露呈。 |
| 2024-07-30 | us-east-1 | 未詳 | Kinesis Data Streams障害;リアルタイムデータ処理アプリケーションに連鎖影響。 | 詳細非公開 | ストリーム処理依存のリスクを浮き彫りに。 |
| 2025-02 | eu-north-1 (ストックホルム) | 未詳 | 1つのAZで重大なネットワーク障害;欧州のコアサービスに影響。 | 大規模ネットワーク障害 | 地域限定;欧州インフラ拡張の課題を反映。 |
| 2025-10-19/20 | us-east-1 | 15時間以上 | DynamoDB APIエンドポイント障害(DNS障害);Slack、Reddit、Roblox、Fortnite、Coinbase、Venmo、Duolingo、Canva、PSN、銀行、航空会社(Delta/United遅延)、Amazon系サービスに影響;3500社以上、60カ国以上、1700万件超の報告。 | DNS解決障害による連鎖反応 | 2025年最大のクラウド障害;「クラウドの脆弱性が最も露呈した事件」;マルチクラウド戦略が強く推奨される。 |
最も深刻な障害の分析
2014〜2025年で最も深刻だったのは2015年9月(DynamoDB)、2017年2月(S3)、特に2025年10月(DynamoDB DNS)の3件。すべてus-east-1で発生。
深刻度順:
- 2015年:エンタメ・SNSに大きな打撃だが、主に消費者向け。
- 2017年:生産性ツール・開発者に甚大な影響;人的ミスによる経済損失が極めて大きい。
- 2025年:最長時間(15時間超)、最も広範(金融、ゲーム、教育、航空、重要インフラ)、ユーザー影響最大 — 近年最大の単一クラウド障害と評価。
共通教訓:us-east-1への過度な集中、コントロールプレーンの脆弱性、連鎖障害。業界はマルチリージョン、マルチクラウド、ハイブリッドアーキテクチャの採用を強く推奨している。
アリババクラウドの障害
2014年から2025年まで、アリババクラウドが公表・公式開示した影響範囲が広く、継続時間が長く、「重大事故」と広く呼ばれた障害は(体量に比べ)特に多くはなく、全体のSLAは業界トップクラスである。ただしそのうち数件は社会的影響と業界議論を引き起こした。以下は重大級の障害の時系列リスト(主に公開情報・公式発表・メディア・コミュニティの振り返りに基づく):
| 時期 | 地域/範囲 | 継続時間 | 主な影響と結果 | 公式/主流の原因 | 備考/業界評価 |
|---|---|---|---|---|---|
| 2018年6月 | 一部地域(詳細非公開) | 約30分 | 一部クラウド製品異常、影響は限定的 | 詳細非公開 | 当時メディアにより「重大技術障害」と呼ばれた |
| 2019年3月3日 | 華北2(北京)AZ-C | 数時間 | ECSディスク障害多発、多数サイト/アプリ停止 | ディスク障害 | 影響大、アリババクラウドはSLAに基づき賠償 |
| 2022年12月18日 | 香港リージョンAZ-C | 約15.5時間 | 香港域ほぼ全域停止、マカオの重要機関(金融管理局、銀河、蓮花衛視等)サイト不通、OKX影響 | 冷却設備故障→連鎖反応で大規模ダウン | 「アリババクラウド史上最悪の醜聞の一つ」と広く称された |
| 2023年11月12日 | 全世界域・全サービス | 約3時間16分 | コンソール・API・MQ・マイクロサービス・監視・ML等ほぼ全線異常;淘宝・釘釘・閑魚・餓了么・阿里雲盤等一斉「クラッシュ」 | 基盤コアコンポーネント(認証/メタデータ/コントロールプレーン)障害 | アリババクラウド史上最悪・影響最広と公認;「エピック」「業界前例なし」 |
| 2023年11月27日 | 一部サーバー | 約2時間 | サーバーアクセス異常 | 詳細非公開 | 11・12事故の半月後、信頼への疑問再燃 |
| 2024年7月2日 | 一部地域/サービス | 数時間 | コンソール及び一部サービス異常 | 詳細な振り返りなし | 中規模、以前の数件より影響小 |
| 2025年(日付不明) | グローバル(DNS関連疑い) | 約6時間 | DNSハイジャックによりグローバルサービス異常 | DNSハイジャック関連 | 2025年パブリッククラウド障害まとめより、詳細要確認 |
重要な注記とトレンド
-
2014–2018年初期:この期間のアリババクラウドの重大P0級障害の公表は極めて少なく、局所・小規模が中心。当時は体量が今よりはるかに小さく、影響も限定的だった。
- 最悪の二件:
- 2022.12 香港15.5時間 → 単一地域最長障害、港澳の重要インフラに悪影響。
- 2023.11.12 グローバル3時間超 → コントロールプレーン/グローバルサービス全面停止;「全地域×全サービス」同時故障として稀とされ、「マルチアクティブ・マルチセンター・Nナイン」神話を打ち砕いた。
-
2024–2025:既知の情報では、2022–2023より頻度・深刻度は低下しているが、中〜大規模事象は依然発生(特に2025年DNSハイジャック系は影響範囲が広い)。
- アリババクラウドの対応:重大障害の多くで詳細な振り返りを公表(特に2022香港・2023グローバル);SLA賠償(通常は障害時間に応じた倍率のバウチャー);幹部/公式の謝罪。
全体として、2014–2025年の12年間でアリババクラウドが「重大事故」と呼べるのはおおよそ5〜7件、その中で2023年11月12日と2022年12月香港が影響力・深刻度で最も高いと公認されている。
グーグルクラウドの障害
Google Cloud Platform(GCP)は2014年から2025年まで、全体のSLAは比較的良好で、グローバルまたは複数コアサービスに真に影響した重大事故は(AWS・Azureに比べグローバル災害級は少ないが)発生時には多くのサードパーティアプリ(Snapchat、Spotify、Discord、Cloudflare依存サービス等)を巻き込み、社会的影響が大きい。
以下は深刻で影響範囲の広いGCP重大障害の時系列リスト(公開Status Dashboard・メディア・Wikipedia・業界振り返り等に基づく):
| 時期 | 地域/範囲 | 継続時間 | 主な影響と結果 | 主流の原因 | 備考/業界評価 |
|---|---|---|---|---|---|
| 2015年8月 | 欧州(ベルギーGhlin) | 数時間 | Compute Engine 読み書きエラー率極高、一部データ損失 | 落雷でデータセンター一部機器損傷 | グーグルがデータ損失を認めた稀有な例、影響は限定的顧客群 |
| 2018年7月 | グローバル(多地域) | 数時間 | GCP多サービス異常、Snapchat・Spotify等サードパーティが広範囲でログイン/利用不可 | ネットワーク輻輳+内部ルーティング | 当時広く報道、サードパーティ影響が顕著 |
| 2019年6月2日 | 米東部+グローバル波及 | 約4–5時間 | YouTube・Gmail・G Suite広範囲不可用、Snapchat・Discord・Vimeo等ログイン失敗 | 米東部ネット輻輳+カスケード | 影響範囲広、SNSで話題 |
| 2020年12月14日 | グローバル | 約1時間 | Gmail・YouTube・Google Home・Nest・Pokémon GO等、認証依存サービスがほぼ全滅 | 認証システム(IAM相当)グローバル障害 | コンシューマサービス一斉「クラッシュ」、最大級の一つ |
| 2022年8月 | 米アイオワ州データセンター | 局所 | 電気火災(負傷3名)、一部サービス波及、グローバルではない | データセンター電気事故による火災 | 物理施設事故、純粋なソフト/アーキテクチャ問題ではない |
| 2023年4月 | 欧州(パリ等) | 数時間 | 多地域ネット+サービス中断 | 洪水+データセンター+ネット問題 | 気象要因、影響は中程度 |
| 2024年10月23日 | 欧州(フランクフルト europe-west3) | 約半日(12時間超) | 当該地域ほぼ全サービス不可、欧州顧客多数に影響 | 詳細非公開(コントロールプレーン/ネット疑い) | 単一地域最長障害の一つ |
| 2025年6月12日 | グローバル(40超地域) | 約2.5–3時間 | 70超GCPサービス異常、IAM認証崩壊でAPIリクエスト全面失敗;Spotify・Discord・Twitch・Cloudflare・Fitbit・Gmail・Drive・YouTube等広範囲停止 | Service Control(API認証コア)の自動更新が深刻バグ導入→クラッシュループ→グローバル過負荷 | 2020年以降GCP最悪のグローバル障害と公認 |
| 2025年7月18日 | us-east1 | 約2時間 | 複数製品エラー率上昇 | 詳細非公開 | 中規模、回復は比較的速い |
Azureの障害
Microsoft Azureは2014年から2025年まで、影響範囲が広く、継続時間が長く、社会的注目が高い重大事故の数は(初期の小規模時の頻繁な小障害に比べ)特に多くはないが、数件はグローバルまたは多サービス級の深刻な影響を与え、Microsoft 365・Teams・Xbox・Outlook等のコンシューマ/エンタープライズ製品が絡むと伝播効果が非常に大きい。
以下は重大級Azure障害の時系列リスト(Azure公式Status History・Post Incident Review・メディア・Wikipedia・業界振り返り等の公開情報に基づく):
| 時期 | 地域/範囲 | 継続時間 | 主な影響と結果 | 主流の原因 | 備考/業界評価 |
|---|---|---|---|---|---|
| 2014年8月14–18日 | US Central・US East・US East 2・Europe North | 複数日・1回数時間 | Cloud Services・SQL Database・VM・Websites・HDInsight・Mobile Services・Service Bus等広範囲不可用 | 複数ネット/ストレージ問題 | 2014年最も集中した一波、当時Azureはまだ若い |
| 2014年11月18–19日 | 多地域(米・欧・アジア一部) | 約11時間 | Azure Storageを中心にVM・Websites・Visual Studio Online・Xbox Live・MSN・Search等20超サービス中断 | ストレージ性能最適化の設定変更→Blobフロント無限ループ | Azure初期最悪の一件、公式詳細RCA、顧客賠償 |
| 2016年9月15日 | グローバル | 数時間 | DNS解決広範囲障害、Azure DNS依存サービス多数に影響 | グローバルDNS問題 | DNS単点リスク露呈 |
| 2018年6月20日 | 北米複数データセンター | 数時間–1日超 | 冷却系故障(落雷+サージ保護不足)で多サービス中断 | 物理施設(落雷連鎖) | 稀なハードウェア/インフラ級障害 |
| 2018年9月4日 | 多地域 | 25時間超(一部サービス3日) | 複数コアサービス長時間不可用 | 冷却(落雷+サージ) | 回復最長の一つ |
| 2023年1月23日 | グローバル(コアネット影響) | 約3時間 | Microsoft 365(Teams・Outlook・Exchange)、一部Azureサービス中断 | WAN問題 | M365一斉「クラッシュ」、影響巨大 |
| 2024年7月18日 | US Central | 約半日 | VM等の管理操作失敗、顧客がマネージドサービスにアクセス不可 | アクセス制御エラー+インフラ障害 | 翌日CrowdStrike全球ブルースクリーンに近接するが独立 |
| 2025年1月8–9日 | East US 2等 | 数時間 | Azure Databricks・Synapse・Functions・App Service・VM等ネット中断 | ネットワークコンポーネント問題 | 2025年序盤で顕著な一件 |
| 2025年10月29日 | グローバル | 約8時間 | Azure Front Doorを中心にMicrosoft 365・Outlook・Teams・Xbox Live・Minecraft・Copilot広範囲停止;Alaska Airlines・Heathrow・Costco・Starbucks等波及 | Azure Front Door設定変更+保護機構のバグで設定不整合がグローバル伝播 | 2025年Azure最悪、Downdetector3万超報告、同月AWS障害に類似 |
| 2025年11月5–6日 | West Europe (AZ01) | 約9–10時間 | VM・PostgreSQL/MySQL Flexible Server・AKS・Storage・Service Bus等多サービス劣化/中断 | データセンター熱イベント | リージョン級で深刻な障害 |
観察とトレンド(2014–2025)
- 2014年:Azureは急拡大期;設定変更とストレージ層問題が頻発、障害が最も集中した年(特に11月は古典的ケース)。
- 2015–2019:障害頻度は低下、依然単一地域またはインフラ(冷却・落雷・DNS)が中心、影響は比較的抑制。
- 2020–2023:重大グローバル障害は少なめ、ネットまたはM365のAzure依存による間接影響(例:2023年1月)が中心。
- 2024–2025:コントロールプレーン/エッジ(Azure Front Door等)が新たな痛み;2025年10月29日は近年Azure最悪のグローバル中断とされ、アリババ2023年11月やGCP 2025年6月に匹敵。
- 典型:重大事故のたびに詳細なPost Incident Review (PIR) を公表、透明性が高い;設定変更・コントロールプレーン・ネットが原因となることが多く(単なるハード障害ではない);M365・Xbox・Teamsが落ちるとサードパーティ伝播が極めて大きい;SLA賠償(クレジット)、顧客は事業継続性を最重視。
全体として、Azureは2014–2025年の12年間で重大級(グローバル/多サービス長時間中断)はおおよそ8–10件、深刻度・頻度はAWS・GCPと同水準で、設定ミスによるカスケードが繰り返し現れるパターン。
Cloudflareの障害
Cloudflareは世界最大級のCDN・セキュリティ・DNS・エッジプロバイダーの一つとして、2014年から2025年まで影響範囲が広くインターネット大規模麻痺を引き起こした重大事故は特に多くはないが、一度起きると数百万〜数億ユーザーに波及し(Cloudflareは全世界の約20–25%のウェブトラフィックを担う)、影響範囲が極めて広い。
特徴は回復が比較的速い(多くは1–4時間で緩和)一方で伝播が極端——コアプロキシ・DNS・セキュリティコンポーネントが落ちると、X・ChatGPT・Shopify・Discord・Spotify・AWS一部等のトップサイトが同時に5xxやアクセス不可になる。
以下は重大級Cloudflare障害の時系列リスト(公式ブログ・status.cloudflare.com履歴・メディア・Wikipedia・業界振り返り、グローバル/コアトラフィック中断に焦点):
| 時期 | 範囲 | 継続時間 | 主な影響と結果 | 主流の原因 | 備考/業界評価 |
|---|---|---|---|---|---|
| 2019年7月2日 | グローバル | 約1–2時間 | 多数サイトで502/503/504、インターネットの広域がアクセス不可 | ソフトウェアデプロイが深刻バグを導入→プロキシ層クラッシュ | Cloudflare史上最悪と公認、公式詳細振り返り |
| 2020年複数回 | 一部地域/コントロールプレーン | 数時間 | ダッシュボード・分析・一部API不可;コアプロキシはほぼ安定 | コントロールプレーン問題 | 開発者への影響大、一般ユーザーは感知小 |
| 2022年6月 | 複数データセンター(19) | 約1.5時間 | コアプロキシ中断、多数サイトアクセス不可 | ネットワーク設定エラー | 中規模、回復は速い |
| 2025年3月21日 | グローバル | 約1時間7分 | ストレージ読み書き深刻障害、ストレージ/キャッシュ依存サービス多数に影響 | KV/ストレージ層書き込み失敗+一部読み異常 | 2025年序盤で顕著 |
| 2025年6月12日 | グローバル(一部機能) | 数時間 | 一部機能/サービス不可、コアトラフィックはほぼ正常 | 特定モジュールデプロイ | コアトラフィック中断ではなく影響は限定的 |
| 2025年7月14日 | グローバル(1.1.1.1 DNS) | 約62分 | パブリックDNSリゾルバ(1.1.1.1)完全不可、多数ユーザーがインターネット接続不可 | 設定エラー→BGPルート撤回→DNSプレフィックスがグローバルルーティングテーブルから消失 | 1.1.1.1依存ユーザーに極めて深刻、「断網級」 |
| 2025年10月頃 | 一部サービス | 数十分 | DNS解決の短時間中断 | DNS関連設定 | 中規模 |
| 2025年11月18日 | グローバル | 約4–5時間(ピークはより長い) | 大規模インターネット中断:X(Twitter)・ChatGPT・Shopify・Spotify・Letterboxd・Indeed・Canva・Uber・DoorDash・Truth Social・League of Legends等多数トップサービス麻痺;約20%ウェブトラフィック、Alexa上位1万サイトの1/3が影響 | Bot Managementルールファイル異常肥大(DB権限変更でファイルサイズ倍増)→全网伝播→プロキシクラッシュ | 2025年最悪、2019年以来最悪のグローバルトラフィック中断 |
| 2025年12月5日 | グローバル | 数時間 | 再び広範囲5xx;Shopify・Zoom・Vinted・Fortnite・Square・Just Eat・Canva・Vimeo・AWS一部・Deliveroo等影響 | 完全な公式根因なし(設定/伝播類疑い) | 11月18日からわずか17日、連続二回の重大事故で強い批判 |
観察とトレンド(2014–2025)
- 2014–2018年初期:Cloudflareは急成長;公表されたグローバル重大障害は少なく、局所・地域・機能問題が中心;当時インターネットのCloudflare依存度は今より低い。
- 2019年7月:Cloudflare史上の古典的「ブラックスワン」;その後6年以上、同規模のコアプロキシ全局中断はなし。
- 2025年は異常な年:少なくとも3–4回の影響の大きいグローバル/準グローバル事象(特に11月18日と12月5日の連続)。11月18日は2019年以来最悪と公認。12月5日の再発で、変更管理・ロールバック・「fail small」の実行が疑問視された。
- 典型:深刻な障害の多くが設定変更・ルール/伝播・コントロールプレーンまたはDNS/BGPに関連;blog.cloudflare.comで毎回詳細なpost-mortem(根因・タイムライン・改善策)を公開、透明性が高い;回復は通常速い(ロールバック+伝播停止)が影響は極めて広い(Anycast+チャレンジ機構);AWS/Azure/Googleのような明確なSLAクレジット賠償はないが、詳細説明と改善コミットを提供。
全体として、Cloudflareは2014–2025年の12年間で重大級(グローバルコアトラフィック長時間中断)はおおよそ5–7件、2019年7月と2025年11月18日が二つのピーク。2025年は障害頻度が明らかに上昇し、「インターネットインフラ集中化リスク」の議論が再燃した。
テンセントクラウドの障害
テンセントクラウドは2014年から2025年まで、中国第二のパブリッククラウド(アリババに次ぐ)として、国内クラウドベンダーの中では安定性は中〜上で、影響が極めて広く、継続時間が長く、社会的注目が高いグローバル/多地域重大事故は相対的に少ないが、コントロールプレーン(コンソール/API)やコアストレージに問題が起きると、影響は多数の企業・開発者に急速に拡大する。
テンセントクラウドのステータスページ(https://status.cloud.tencent.com/history)の公開透明性は比較的低く、履歴は通常直近1年のみで、中〜大規模障害の多くは一覧に載らず、公式微信・技術ブログ・メディア・コミュニティで全体像を補う。
以下は深刻で影響範囲の広いテンセントクラウド障害の時系列リスト(公式振り返り・メディア・知乎/微博/開発者コミュニティ等の公開情報に基づく):
| 時期 | 地域/範囲 | 継続時間 | 主な影響と結果 | 主流の原因 | 備考/業界評価 |
|---|---|---|---|---|---|
| 2014年11月2日 | 全国(コントロールプレーン+一部サービス) | 約6分 | テンセントクラウド公式サイト遅延・画像読込失敗・コンソール異常、一部ユーザーが正常利用不可 | 詳細非公開(ネット/負荷疑い) | 初期小規模期、影響は限定的だが当時メディアで広く報道 |
| 2018年8月 | 一部ユーザー/クラウドディスク | 不明(単一ユーザーで数時間〜恒久) | 複数ユーザーのクラウドサーバーディスクデータゼロ/消失、千万単位の損失 | ディスク静默エラー+データ移行時の検証/レプリカ機構不全 | テンセントクラウド史上最悪の「データ消失」、クラウド信頼危機、公式詳細振り返り |
| 2023年(散発) | 一部地域/サービス | 数十分–数時間 | 散発的なコンソール/API異常、ストレージジッター | 公開の詳細振り返りなし | アリババ2023年11月グローバルと比べテンセントは比較的安定 |
| 2024年4月8日 | 全球17地域 | 約74–87分 | コンソール完全ログイン不可、クラウドAPI全面504 Gateway Timeout;CVM/RDS等インスタンスは稼働するが管理/更新/スケール不可;1957件の顧客障害報告 | クラウドAPI新バージョンの後方互換不足+設定データのグレーリリース機構欠如→一斉リリースでグローバル伝播 | テンセントクラウド近年最悪、「全球大障害」「コントロールプレーン崩壊」と広く呼ばれ、アリババ2023年11月スタイルに類似 |
| 2025年10月15日 | 多地域 | 約数十分–1時間 | 弹性伸缩(Auto Scaling)等サービス異常 | 詳細非公開 | ステータスページより、中規模 |
| 2025年10月17日 | 広州地域 | 約1時間超 | 智能数智人関連サービス異常 | 詳細非公開 | リージョン級、特定AI/デジタルヒューマン製品 |
観察とトレンド(2014–2025)
- 初期(2014–2018):障害はストレージ層のデータ消失や短時間アクセス異常が典型;2018年「データ消失」が企業信頼を最も痛撃。
- 2019–2023:テンセントクラウドの障害頻度・深刻度は明らかに低下、全国/グローバル級は稀、安定性は同期のアリババより良好(特に2023年アリババ11・12エピック障害時はテンセントは安定)。
- 2024–2025:2024年4月8日が転換点;このコントロールプレーン全局障害で多くの人がテンセントクラウドの「変更安全」と「グレーリリース」能力を再検討。2025年は中規模が数回あるが、2024年4月やアリババ/グーグルクラウドのような「全サービス麻痺」級は見られない。
- 典型:コントロールプレーン/APIが近年の最大の痛み(2024年4月が代表);ストレージ/データ消失が企業への打撃が最大(2018年事例);公式振り返りは比較的タイムリー(重大時は微信・技術コミュニティで詳細説明);AWS/Azure/Googleのような厳格なSLAクレジット賠償はないが、バウチャー/補償を提供;障害の伝播はアリババ・Cloudflareほど劇的ではない(顧客構成が企業/ゲーム/動画寄りで、コンシューマインターネット依存が相対的に低いため)。
全体として、テンセントクラウドは2014–2025年の12年間で重大級(全国/グローバルコントロールプレーン長時間不可または深刻なデータ消失)と呼べるのはおおよそ3–5件、2018年データ消失と2024年4月8日グローバルコントロールプレーン障害が影響力・議論度で最も高い二件とされている。
障害の透明性
障害の透明性という点では、アリババクラウドとテンセントクラウドは比較的弱い。
アリババクラウドのステータスボード(https://status.aliyun.com/#/?region=cn-shanghai)とテンセントクラウドのステータスボード(https://status.cloud.tencent.com/history)は、過去1年間のイベントしか表示しない。
Azure(https://azure.status.microsoft/en-us/status/history/)は5年分を保持。Cloudflare(https://www.cloudflarestatus.com/history?page=17)が最も詳細で透明で、pageで数年分まで遡って閲覧できる。
パブリッククラウドの「死」
若い頃、私は他人のコードを読んでリファクタリングするのが好きだった。Java Boyに教えられるまで:彼のメモリリークを直したのに、彼が感じたのは深い実存的不安だった。彼は怒りで自分の無能を隠し、「Kubernetesプラットフォームの安定維持」の責任を私に押し付けた。
私も彼の尻拭いを喜んでやっていたわけではない。ただ、頻発するOOM killイベントアラートが煩わしかっただけだ。その話から、ゼロの哲学を悟った:限界便益がゼロのリファクタリングは誰もやりたがらない。
ゆえにソフトウェア業界のエントロピー増大の法則が導かれる:プロジェクトのコードベースは時間とともにスパゲッティ化する。
「これがパブリッククラウドの死と何の関係がある?」と聞く人がいた。
実は大いに関係がある。「工業的クトゥルフ」は企業に時間とともに増える利益を要求する。だからパブリッククラウドベンダーとその現場社員は「新しい成長物語」を語らなければならない——2026年なら、その物語はAIだ。
古いコードはそのまま腐る。変更しても限界便益はない。
やがて誰もが同じ合意に至る:他人のコードには触れず、スパゲッティ化に任せる。コードもアーキテクチャも同じ。ネットワークトポロジーが純粋な相互依存の網の目になっても、障害時はみんな使えず、ダウン責任が平等に分散すれば、自分に責任はない。
皮肉なことに、在職中に障害ゼロで毎日「仕事中に寝ている」ように見える運用エンジニアは、無能だと見なされる。何もしていないように見えるから。しかし直感に反して、その人は企業のマスコットとして祀るべきだ。彼が以前どれだけ業務安定のために努力したか、あるいは単に運が良かっただけなのか、誰にもわからない。大廟に配享するに値する。
究極の運用は、運用しないことである。運用の報酬とキャリアリスクは完全に不均衡だからだ。上司は「使っていなさそうな設定」を消しても今月の手当を増やしてくれない。だが「使っているデータベース設定」を消せば、顧客に罵倒される。
パブリッククラウド企業は忘れている。ネットワーク効果は彼らを押し上げることも、叩き落とすこともできる。顧客が増えれば、単一のダウンによるネットワークの連鎖反応は大きくなる。2025年12月4日夜21:00–23:37頃の支付宝障害のように——これは阿里系2025年の第六の重大障害だった。
ユーザー規模が億単位になると、一秒ごとに誰かが支払っている。それでも業務はソフトに新機能を追加し続けを求め、やがてシステムは耐えられなくなる。
しかもパブリッククラウドの賠償は完全に不均衡だ。支付宝のようなケースではせいぜい「多退少補」、少なく徴収した分を福利として返す程度。だが政府・企業の損失は到底算定できない。業務がパブリッククラウドに載っていて、クラウドがダウンしたら、業務側はクラウドにどう自分の損失を説明するのか?
「うちのシステムは一日数百億取引している。数億賠償してくれる?」
顧客の損失は定量化できない。だからアリババクラウドは通常、バウチャーを少し渡すだけだ。それは焼け石に水。失われた時間、実際の業務影響、その時間価値を誰もはっきり言えない。
ネットワーク効果はパブリッククラウドに指数関数的な収益成長をもたらした。しかし大型の政府・企業ユーザーにとっては、パブリッククラウドへの反依存を日程に載せるべきだ。自らの運命を単一のクラウドベンダーに縛れば、突発リスクには対応できない。
小並行・高可用システム
その上で、私は「小並行・高可用システム」を提案する。ストレージの冗長により、業務の高可用性を実現する。
トラフィックが冗長な情報システムに平準に分散されれば、集中型トラフィックによる単一クラスタのトラフィックピークを避け、問題の拡散半径を縮小できる。
最も単純な例。DNS解決の際、広東のDNSを華南地域のアリババ・テンセントKubernetesクラスタに向ける。各クラスタは互いに依存せず、内部で完全な情報業務システムを稼働させる。最悪の場合、パブリッククラウド自体に問題が起きても、不可用は50%までに抑えられる。
両方同時に不可用になる確率は極めて小さい。
Farewell, Public Cloud. See you on the Yangtze River.
参考リンク
【1】
2025年11月18日 Cloudflare サービス中断
https://blog.cloudflare.com/zh-cn/18-november-2025-outage/
【2】
AWS障害から見るDNSの見えざる杀伤力:DeepFlowが混乱の中でいかに素早く根因を特定したか
https://my.oschina.net/u/3681970/blog/18697034
【3】
2023-11-12 アリババクラウド障害の振り返りと分析
https://github.tiankonguse.com/blog/2023/11/29/aliyun-break.html
Резюме
Статья исходит из формальной логики и определений (сетевой эффект, закон возрастания энтропии, антизависимость, философия «нуля» нулевой предельной выгоды), систематически обозревает крупные сбои основных публичных облаков и инфраструктуры — Alibaba Cloud, Google Cloud, Azure, Cloudflare, Tencent Cloud — с 2014 по 2025 год и сравнивает прозрачность их отчётности по сбоям. На этой основе анализируются «причины смерти» публичного облака: энтропия ПО и нулевая предельная выгода затрудняют управление устаревшим кодом и архитектурой; сетевые эффекты усиливают каскадные сбои; компенсации по SLA серьёзно не соответствуют реальным потерям предприятий и госсектора. Автор рекомендует крупным предприятиям и госорганам приоритизировать «антизависимость» от одного публичного облака и предлагает концепцию «высокодоступной системы с малой параллельной нагрузкой» — снижение риска единой точки отказа и радиуса поражения за счёт избыточности хранения и распределения трафика (например, мультирегиональное, мультикластерное DNS-разрешение).
Формальная логика и определения
Сетевой эффект: чем больше пользователей (или участников) у продукта/сервиса/платформы, тем выше его ценность для каждого пользователя.
Закон возрастания энтропии: кодовую базу проекта со временем ожидает превращение в «свалку».
Антизависимость: обратная зависимость от одного языка программирования, стека или облачной платформы. Примеры: полиглот-программирование, мультистек, мультиоблако. Антизависимость позволяет бизнесу стабильно работать без привязки к одному языку, открытому проекту или публичному облаку.
Ноль: рефакторинг с нулевой предельной выгодой никому не нужен.
Сбои AWS
| Время | Регион / Область | Длительность | Основное воздействие и последствия | Официальная / основная причина | Примечания / Оценка отрасли |
|---|---|---|---|---|---|
| 2014-06-13 | us-east-1 (Северная Вирджиния) | Не указано | Затронуты ключевые компоненты Amazon SimpleDB, часть пользователей не могла работать с БД. | Проблема с питанием. | Небольшое событие; быстро восстановлено; показало слабость резервирования питания. |
| 2014-08-07 | EU West (Ирландия) | Не указано | Затронуты EC2, EBS, RDS; европейские клиенты потеряли доступ к инстансам и хранилищам. | Внутреннее системное событие. | Региональное; выявило слабую изоляцию регионов на раннем этапе. |
| 2014-11-26 | Глобально (CloudFront DNS) | ~2 часа | Сбой DNS-серверов CloudFront; многие сайты и сервисы не могли разрешать запросы. | Сбой DNS-серверов. | Короткий, но широкий эффект; показал уязвимость DNS крупнейшего облака. |
| 2015-09-20 | us-east-1 | Несколько часов | Сбой DynamoDB → сбой внутренних коммуникаций; пострадали Netflix, Reddit, IMDb, Amazon. | Цепная реакция внутренних сервисов. | Серьёзный инцидент; миллионы пользователей; предупреждение о сильной связанности сервисов. |
| 2017-02-28 | us-east-1 | 4–5 часов | Поломка контрольной плоскости S3; Slack, Trello, GitHub Pages, Quora и многие сайты без файлов. | Ошибка инженера — удалена критическая конфигурация. | Одна из самых известных аварий; «самая дорогая опечатка в истории». |
| 2020-11-25 | us-east-1 | Несколько часов | Сбой Kinesis и Cognito; пострадали Roku, Adobe, Flickr; стриминг и аутентификация. | Проблема с обновлением ёмкости. | Произошло во время пандемии; подчеркнуло сложности планирования мощностей. |
| 2022-12-05 | us-east-2 (Огайо) | ~40 минут | Сбой зоны доступности; нарушена работа ряда сервисов в регионе. | Не раскрыто подробно (вероятно сеть/питание). | Короткий, но показал важность multi-AZ архитектуры. |
| 2023-06-13 | us-east-1 | Не указано | Сбой Lambda; пострадали Boston Globe, метро Нью-Йорка, Associated Press и др. | Не раскрыто подробно. | Показал уязвимость бессерверных вычислений при масштабе. |
| 2024-07-30 | us-east-1 | Не указано | Сбой Kinesis Data Streams; нарушена обработка данных в реальном времени. | Не раскрыто подробно. | Подчеркнул риски зависимостей потоковой обработки. |
| 2025-02 | eu-north-1 (Стокгольм) | Не указано | Крупный сетевой сбой в одной зоне; нарушены ключевые сервисы в Европе. | Серьёзный сетевой сбой. | Региональное; отразило сложности расширения инфраструктуры в Европе. |
| 2025-10-19/20 | us-east-1 | >15 часов | Сбой точки входа DynamoDB (DNS); пострадали Slack, Reddit, Roblox, Fortnite, Coinbase, Venmo, Duolingo, Canva, PlayStation, банки, авиакомпании (задержки Delta/United), Amazon; >3500 компаний, 60+ стран, >17 млн жалоб. | Сбой разрешения DNS → каскадный эффект. | Крупнейший сбой облака 2025 года; «самое большое обнажение уязвимости облака»; активно продвигают multi-cloud. |
Анализ самых серьёзных инцидентов
Наиболее тяжёлые сбои: 2015 (DynamoDB), 2017 (S3) и особенно 2025-10 (DynamoDB DNS). Все произошли в us-east-1 — самом старом и загруженном регионе AWS.
Рейтинг тяжести:
- 2015 — сильно пострадали развлекательные и социальные платформы.
- 2017 — огромный ущерб продуктивности и разработчикам; рекордные убытки из-за человеческого фактора.
- 2025 — самая длительная (>15 ч), самая широкая (финансы, игры, образование, авиация, критическая инфраструктура) — считается самым серьёзным одиночным облачным сбоем последних лет.
Главные уроки: чрезмерная зависимость от us-east-1, хрупкость контрольной плоскости, каскадные сбои. Отрасль всё активнее рекомендует многорегиональные, мультиоблачные и гибридные архитектуры.
Сбои Alibaba Cloud
С 2014 по 2025 год у Alibaba Cloud не было аномально большого числа крупных инцидентов, широко освещённых и официально раскрытых, действительно широких по охвату, длительных и называемых «крупными авариями» (по масштабу компании общий SLA по-прежнему на уровне лидеров отрасли). Однако несколько из них действительно вызвали заметные общественные последствия и отраслевую дискуссию. Ниже — хронологический список крупных сбоев (по открытым отчётам, официальным заявлениям, СМИ и разборам сообщества):
| Время | Регион/охват | Длительность | Основное влияние и последствия | Официальная/основная причина | Заметки/оценка отрасли |
|---|---|---|---|---|---|
| Июнь 2018 | Часть регионов (детали не раскрыты) | ~30 мин | Сбои части облачных продуктов, ограниченное влияние | Подробно не раскрыто | Часть СМИ назвала «крупным техническим сбоем» |
| 3 марта 2019 | Северный Китай 2 (Пекин) AZ-C | Часы | Массовые сбои дисков ECS, падение множества сайтов/приложений | Сбой дисков | Существенное влияние; Alibaba Cloud компенсировала по SLA |
| 18 декабря 2022 | Регион Гонконг AZ-C | ~15,5 ч | Почти полная остановка Гонконга; недоступность ключевых сайтов Макао (денежно-кредитное управление, Galaxy, Lotus TV и др.); затронут OKX | Отказ охлаждения → каскад → массовый простой | Широко названо «одним из худших инцидентов в истории Alibaba Cloud» |
| 12 ноября 2023 | Все регионы и сервисы глобально | ~3 ч 16 мин | Консоль, API, MQ, микросервисы, мониторинг, ML и др. в сбое; Taobao, DingTalk, Xianyu, Ele.me, Alibaba Cloud Drive и др. упали | Сбой ядра (аутентификация/метаданные/контрольная плоскость) | Широко признано худшим и самым широким сбоем Alibaba Cloud; «эпический», «беспрецедентный в отрасли» |
| 27 ноября 2023 | Часть серверов | ~2 ч | Сбой доступа к серверам | Подробно не раскрыто | Всего через полмесяца после 11·12; новые вопросы к доверию |
| 2 июля 2024 | Часть регионов/сервисов | Часы | Сбои консоли и части сервисов | Детального разбора нет | Средний масштаб; влияние меньше предыдущих |
| 2025 (дата неясна) | Глобально (подозрение на DNS) | ~6 ч | Подмена DNS привела к глобальным сбоям сервисов | Подмена DNS | По сводке сбоев публичного облака 2025; детали уточняются |
Важные замечания и тренды
-
2014–2018, ранний период: Публично раскрытых крупных P0-инцидентов в этот период крайне мало; в основном локальные, ограниченные случаи. Масштаб был намного меньше, влияние — тоже.
- Два самых тяжёлых:
- 2022.12 Гонконг 15,5 ч → Самый длительный сбой в одном регионе; тяжёлое влияние на критическую инфраструктуру Гонконга и Макао.
- 2023.11.12 глобально 3+ ч → Остановка контрольной плоскости и глобальных сервисов; широко признано редким сбоем «все регионы × все сервисы», развенчавшим миф о «мультиактивности, мультицентре, N девяток».
-
2024–2025: По известным данным частота и тяжесть ниже, чем в 2022–2023, но средние и крупные события по-прежнему случаются (например, подмена DNS в 2025 году имела широкий охват).
- Подход Alibaba Cloud: После большинства крупных сбоев публикуются детальные разборы (особенно по Гонконгу 2022 и глобальному 2023); компенсация по SLA (обычно ваучеры); официальные извинения руководства.
В целом за 2014–2025 у Alibaba Cloud порядка 5–7 инцидентов уровня «крупная авария», при этом 12 ноября 2023 и декабрь 2022 Гонконг общепризнанно считаются двумя самыми тяжёлыми.
Сбои Google Cloud
Google Cloud Platform (GCP) с 2014 по 2025 год имел в целом хороший SLA; крупные инциденты, реально затронувшие глобальный охват или несколько ключевых сервисов, не были особенно частыми (меньше глобальных катастроф, чем у AWS и Azure). Когда они происходили, часто страдали многие сторонние приложения (Snapchat, Spotify, Discord, сервисы, зависящие от Cloudflare и т.д.) с высоким общественным резонансом.
Ниже — хронологический список серьёзных, широких по охвату сбоев GCP (по открытому Status Dashboard, СМИ, Wikipedia, отраслевым разборам):
| Время | Регион/охват | Длительность | Основное влияние и последствия | Основная причина | Заметки/оценка отрасли |
|---|---|---|---|---|---|
| Август 2015 | Европа (Глин, Бельгия) | Часы | Очень высокая доля ошибок чтения/записи Compute Engine; частичная потеря данных | Молния повредила часть ЦОД | Google редко признаёт потерю данных; ограниченный круг заказчиков |
| Июль 2018 | Глобально (несколько регионов) | Часы | Сбои сервисов GCP; Snapchat, Spotify и др. в основном недоступны | Перегрузка сети + внутренняя маршрутизация | Широко освещено; сильное влияние на третьи стороны |
| 2 июня 2019 | Восток США + глобально | ~4–5 ч | Массовые сбои YouTube, Gmail, G Suite; сбои входа Snapchat, Discord, Vimeo | Перегрузка сети на востоке США + каскад | Широкий охват; активное обсуждение в соцсетях |
| 14 декабря 2020 | Глобально | ~1 ч | Gmail, YouTube, Google Home, Nest, Pokémon GO и др. — почти все сервисы, зависящие от аутентификации, упали | Глобальный сбой системы идентификации (аналог IAM) | «Падение» потребительских сервисов; один из худших |
| Август 2022 | ЦОД в Айове | Локально | Электрический пожар (3 пострадавших); затронуты часть сервисов, не глобально | Электрический пожар в ЦОД | Физический объект; не чисто софт/архитектура |
| Апрель 2023 | Европа (Париж и др.) | Часы | Сбои сети и сервисов в нескольких регионах | Наводнение + ЦОД + сетевые проблемы | Погодный фактор; среднее влияние |
| 23 октября 2024 | Европа (Франкфурт europe-west3) | ~12+ ч | Регион в основном недоступен; затронуты многие европейские заказчики | Подробно не раскрыто (подозрение на контрольную плоскость/сеть) | Один из самых длительных сбоев в одном регионе |
| 12 июня 2025 | Глобально (40+ регионов) | ~2,5–3 ч | Сбои 70+ сервисов GCP; падение IAM → сбои API-запросов; Spotify, Discord, Twitch, Cloudflare, Fitbit, Gmail, Drive, YouTube и др. упали | Service Control (ядро API-аутентификации): автоматическое обновление внесло тяжёлый баг → цикл сбоев → глобальная перегрузка | Широко признано худшим глобальным сбоем GCP с 2020 года |
| 18 июля 2025 | us-east1 | ~2 ч | Повышенная доля ошибок у нескольких продуктов | Подробно не раскрыто | Средний масштаб; восстановление относительно быстрое |
Сбои Azure
У Microsoft Azure с 2014 по 2025 год не было аномально большого числа крупных инцидентов, широких по охвату, длительных и привлекающих внимание (по сравнению с ранним периодом частых мелких сбоев при меньшем масштабе ситуация улучшилась). Несколько событий действительно привели к глобальному или мультисервисному влиянию, особенно когда были затронуты Microsoft 365, Teams, Xbox, Outlook и другие потребительские/корпоративные продукты; эффект распространения был очень заметен.
Ниже — хронологический список крупных сбоев Azure (по Azure Status History, Post Incident Reviews, СМИ, Wikipedia, отраслевым разборам):
| Время | Регион/охват | Длительность | Основное влияние и последствия | Основная причина | Заметки/оценка отрасли |
|---|---|---|---|---|---|
| 14–18 августа 2014 | US Central, US East, US East 2, Europe North | Несколько дней, часы за событие | Cloud Services, SQL Database, VM, Websites, HDInsight, Mobile Services, Service Bus в основном недоступны | Несколько сетевых/хранилищных проблем | Самая концентрированная волна 2014 года; Azure ещё молодой |
| 18–19 ноября 2014 | Несколько регионов (США, ЕС, Азия) | ~11 ч | В центре Azure Storage; VM, Websites, Visual Studio Online, Xbox Live, MSN, Search, 20+ сервисов упали | Изменение конфигурации производительности хранилища → бесконечный цикл фронта Blob | Худший ранний инцидент Azure; детальный RCA; компенсация заказчикам |
| 15 сентября 2016 | Глобально | Часы | Массовый сбой разрешения DNS; затронуты многие сервисы, зависящие от Azure DNS | Глобальная проблема DNS | Обнажён риск единой точки отказа DNS |
| 20 июня 2018 | Несколько ЦОД в Северной Америке | Часы–1+ день | Сбой охлаждения (молния + защита от перенапряжения) → сбои нескольких сервисов | Физический объект (каскад от молнии) | Редкий инцидент уровня железа/инфраструктуры |
| 4 сентября 2018 | Несколько регионов | 25+ ч (часть сервисов 3 дня) | Ключевые сервисы длительно недоступны | Охлаждение (молния + перенапряжение) | Одно из самых длительных восстановлений |
| 23 января 2023 | Глобально (ядро сети) | ~3 ч | Microsoft 365 (Teams, Outlook, Exchange), часть сервисов Azure упали | Проблема WAN | «Падение» M365; огромное влияние |
| 18 июля 2024 | US Central | ~Полдня | Сбои операций управления VM и др.; заказчики не могли получить доступ к управляемым сервисам | Ошибка контроля доступа + сбой инфраструктуры | Близко по времени к глобальному BSOD CrowdStrike на следующий день, но независимо |
| 8–9 января 2025 | East US 2 и др. | Часы | Сбои сети Azure Databricks, Synapse, Functions, App Service, VM | Проблема сетевого компонента | Заметный инцидент начала 2025 года |
| 29 октября 2025 | Глобально | ~8 ч | В центре Azure Front Door; Microsoft 365, Outlook, Teams, Xbox Live, Minecraft, Copilot упали; затронуты Alaska Airlines, Heathrow, Costco, Starbucks и др. | Изменение конфигурации Azure Front Door + баг защиты → несовместимая конфигурация распространилась глобально | Худший инцидент Azure в 2025 году; Downdetector 30k+ отчётов; похоже на сбой AWS в том же месяце |
| 5–6 ноября 2025 | West Europe (AZ01) | ~9–10 ч | Деградация/остановка VM, PostgreSQL/MySQL Flexible Server, AKS, Storage, Service Bus | Тепловой инцидент в ЦОД | Серьёзный региональный сбой |
Наблюдения и тренды (2014–2025)
- 2014: Azure в фазе быстрого роста; частые проблемы изменений конфигурации и слоя хранилища; самый концентрированный по сбоям год (ноябрьский инцидент — классический кейс).
- 2015–2019: Частота сбоев снизилась; по-прежнему в основном один регион или инфраструктура (охлаждение, молния, DNS); влияние относительно ограничено.
- 2020–2023: Крупных глобальных сбоев мало; чаще сеть или зависимость M365 от Azure (напр., январь 2023).
- 2024–2025: Контрольная плоскость/край (напр. Azure Front Door) стал новой болевой точкой; 29 октября 2025 широко признано худшей глобальной остановкой Azure за последние годы, сопоставимой с Alibaba ноябрь 2023 или GCP июнь 2025.
- Типичные черты: Детальный Post Incident Review (PIR) после крупных инцидентов; изменение конфигурации, контрольная плоскость, сеть часто в корне (не только железо); сильное распространение на третьи стороны при сбоях M365, Xbox, Teams; компенсация по SLA (кредит); заказчики больше всего заботятся о непрерывности бизнеса.
В целом у Azure за 2014–2025 порядка 8–10 крупных (глобальных/мультисервисных, длительных) сбоев; тяжесть и частота на одном уровне с AWS и GCP; каскадный сбой из-за ошибки конфигурации — повторяющийся сценарий.
Сбои Cloudflare
Cloudflare как один из крупнейших в мире CDN, безопасности, DNS и edge-провайдеров с 2014 по 2025 год не имел аномально большого числа крупных инцидентов, вызвавших широкий сбой интернета. Когда они происходили, влияние достигало миллионов и сотен миллионов пользователей (Cloudflare обрабатывает ~20–25% мирового веб-трафика).
Типичная картина: восстановление часто быстрое (большинство ослабевает за 1–4 ч), но распространение крайне сильное — при сбое ядра прокси, DNS или компонентов безопасности многие топовые сайты (X, ChatGPT, Shopify, Discord, Spotify, части AWS и т.д.) одновременно получают 5xx или становятся недоступны.
Ниже — хронологический список крупных сбоев Cloudflare (по официальному блогу, истории status.cloudflare.com, СМИ, Wikipedia; фокус на глобальных/ядровых трафиковых событиях):
| Время | Охват | Длительность | Основное влияние и последствия | Основная причина | Заметки/оценка отрасли |
|---|---|---|---|---|---|
| 2 июля 2019 | Глобально | ~1–2 ч | Массовые 502/503/504 на сайтах; большие части интернета недоступны | Внедрение софта внесло тяжёлый баг → падение слоя прокси | Широко признано худшим за всю историю Cloudflare; детальный разбор |
| 2020, несколько раз | Часть регионов/контрольная плоскость | Часы | Недоступны дашборд, аналитика, часть API; ядро прокси в основном стабильно | Проблемы контрольной плоскости | Больше влияния на разработчиков; обычные пользователи меньше замечают |
| Июнь 2022 | Несколько ЦОД (19) | ~1,5 ч | Остановка ядра прокси; множество сайтов недоступны | Ошибка конфигурации сети | Средний масштаб; быстрое восстановление |
| 21 марта 2025 | Глобально | ~1 ч 7 мин | Сильные сбои чтения/записи хранилища; затронуты многие сервисы, зависящие от хранилища/кэша | Сбой записи слоя KV/хранилища + частичные проблемы чтения | Заметный инцидент начала 2025 года |
| 12 июня 2025 | Глобально (часть функций) | Часы | Часть функций/сервисов недоступна; ядро трафика в основном в порядке | Внедрение определённого модуля | Не остановка ядра трафика; ограниченное влияние |
| 14 июля 2025 | Глобально (DNS 1.1.1.1) | ~62 мин | Публичный DNS-резолвер (1.1.1.1) полностью недоступен; многие пользователи не могли выйти в интернет | Ошибка конфигурации → отзыв BGP-маршрута → префикс DNS исчез из глобальной таблицы маршрутизации | Очень тяжело для пользователей 1.1.1.1; уровень «обрушения интернета» |
| ~Октябрь 2025 | Часть сервисов | Десятки минут | Краткий сбой разрешения DNS | Проблема конфигурации DNS | Средний масштаб |
| 18 ноября 2025 | Глобально | ~4–5 ч (пик дольше) | Крупная остановка интернета: X (Twitter), ChatGPT, Shopify, Spotify, Letterboxd, Indeed, Canva, Uber, DoorDash, Truth Social, League of Legends и др.; ~20% веб-трафика; 1/3 сайтов из топ-10k Alexa | Аномальный рост файла правил Bot Management (изменение прав БД → удвоение размера файла) → глобальное распространение → падение прокси | Худший в 2025 году; также худшая глобальная остановка трафика с 2019 года |
| 5 декабря 2025 | Глобально | Часы | Снова массовые 5xx; затронуты Shopify, Zoom, Vinted, Fortnite, Square, Just Eat, Canva, Vimeo, части AWS, Deliveroo и др. | Полной официальной первопричины нет (подозрение на конфигурацию/распространение) | Всего через 17 дней после 18 ноября; два крупных инцидента подряд вызвали сильную критику |
Наблюдения и тренды (2014–2025)
- 2014–2018: Cloudflare быстро рос; публичных крупных глобальных инцидентов мало; в основном локальные/региональные/функциональные проблемы; зависимость интернета от Cloudflare была ниже, чем сейчас.
- Июль 2019: Стал классическим «чёрным лебедем» Cloudflare; более шести лет не было глобальной остановки ядра прокси сопоставимого масштаба.
- 2025 как аномальный год: Не менее 3–4 широких глобальных/почти глобальных событий (особенно 18 ноября и 5 декабря подряд). 18 ноября широко признано худшим с 2019 года. 5 декабря снова заставило многих усомниться в контроле изменений, откате и принципе «fail small».
- Типичные черты: Большинство тяжёлых инцидентов связаны с изменением конфигурации, правилами/распространением, контрольной плоскостью или DNS/BGP; очень прозрачные разборы на blog.cloudflare.com; восстановление обычно быстрое (откат + остановка распространения), но влияние очень широкое (Anycast + механизм вызова); нет явной компенсации по SLA как у AWS/Azure/Google, но есть детальные объяснения и обязательства по улучшениям.
В целом у Cloudflare за 2014–2025 порядка 5–7 крупных (глобальная ядровая трафиковая, длительная) сбоев; июль 2019 и 18 ноября 2025 — два пиковых события. В 2025 году частота сбоев заметно выросла, возобновилось обсуждение «риска концентрации интернет-инфраструктуры».
Сбои Tencent Cloud
Tencent Cloud с 2014 по 2025 год как второй по размеру публичный облачный провайдер Китая (после Alibaba Cloud) имел в целом хорошую стабильность среди местных провайдеров. Действительно широких, длительных, привлекающих внимание глобальных/мультирегиональных крупных инцидентов было относительно немного; при сбое контрольной плоскости (консоль/API) или ключевого хранилища влияние быстро распространялось на множество предприятий и разработчиков.
Страница статуса Tencent Cloud (https://status.cloud.tencent.com/history) относительно непрозрачна: история часто показывает только последний год, многие средние и крупные инциденты отсутствуют; полная картина складывается из официального WeChat, техблога, СМИ и сообщества.
Ниже — хронологический список серьёзных, широких по охвату инцидентов Tencent Cloud (по официальным разборам, СМИ, Zhihu/Weibo/сообществу разработчиков):
| Время | Регион/охват | Длительность | Основное влияние и последствия | Основная причина | Заметки/оценка отрасли |
|---|---|---|---|---|---|
| 2 ноября 2014 | По стране (контрольная плоскость + часть сервисов) | ~6 мин | Медленный сайт Tencent Cloud, сбой загрузки изображений, сбой консоли; часть пользователей не могла нормально пользоваться | Подробно не раскрыто (подозрение на сеть/нагрузку) | Ранний период малого масштаба; влияние ограничено, но тогда широко освещено |
| Август 2018 | Часть пользователей/облачный диск | Неясно (влияние на одного пользователя часы до постоянного) | Обнуление/потеря данных облачного диска у нескольких пользователей; убытки порядка десятков миллионов | Тихий сбой диска + сбой проверки/реплики при миграции | Худший инцидент «потери данных» в истории Tencent Cloud; кризис доверия; детальный разбор |
| 2023 (отдельные сообщения) | Часть регионов/сервисов | Десятки мин–часы | Отдельные сбои консоли/API, джиттер хранилища | Детального публичного разбора нет | По сравнению с глобальным сбоем Alibaba в ноябре 2023 Tencent был относительно стабилен |
| 8 апреля 2024 | 17 регионов глобально | ~74–87 мин | Консоль полностью недоступна; облачный API 504 Gateway Timeout; инстансы CVM/RDS работают, но управление/продление/масштабирование невозможно; 1957 обращений заказчиков | Обратная несовместимость новой версии API + отсутствие механизма поэтапного раскрытия конфигурации → полный выкат → глобальное распространение | Самый тяжёлый за последние годы у Tencent Cloud; широко названо «глобальной аварией», «обрушением контрольной плоскости»; стиль похож на Alibaba ноябрь 2023 |
| 15 октября 2025 | Несколько регионов | ~Десятки мин–1 ч | Сбои Auto Scaling и других сервисов | Подробно не раскрыто | Со страницы статуса; средний масштаб |
| 17 октября 2025 | Гуанчжоу | ~1+ ч | Сбои сервисов, связанных с AI digital-human | Подробно не раскрыто | Региональный; конкретный продукт AI/цифровой человек |
Наблюдения и тренды (2014–2025)
- Ранний период (2014–2018): Сбои часто потеря данных хранилища или краткие проблемы доступа; инцидент «потери данных» 2018 года сильнее всего ударил по доверию предприятий.
- 2019–2023: Частота и тяжесть сбоев Tencent Cloud снизились; общенациональных/глобальных событий мало; стабильность выше, чем у Alibaba в тот же период (напр., спокойно во время 11·12 у Alibaba).
- 2024–2025: 8 апреля 2024 стало переломным; глобальный сбой контрольной плоскости заставил многих переоценить «безопасность изменений» и «поэтапный выкат». В 2025 было несколько средних инцидентов, но ничего уровня «полная остановка сервисов» как в апреле 2024 или у Alibaba/Google.
- Типичные черты: Контрольная плоскость/API — главная болевая точка (апрель 2024); хранилище/потеря данных наиболее разрушительны для предприятий (2018); разборы относительно своевременны (WeChat, техсообщество); нет строгой компенсации по SLA как у AWS/Azure/Google, но есть ваучеры/компенсация; распространение сбоя менее драматично, чем у Alibaba/Cloudflare (клиентская база более корпоративная/игры/видео, меньше зависимость от потребительского интернета).
В целом у Tencent Cloud за 2014–2025 порядка 3–5 крупных (общенациональная/глобальная контрольная плоскость длительно недоступна или серьёзная потеря данных) инцидентов; потеря данных 2018 и глобальный сбой контрольной плоскости 8 апреля 2024 — два самых обсуждаемых.
Прозрачность по сбоям
С точки зрения прозрачности по сбоям Alibaba Cloud и Tencent Cloud относительно слабы.
Доска статуса Alibaba Cloud (https://status.aliyun.com/#/?region=cn-shanghai) и Tencent Cloud (https://status.cloud.tencent.com/history) показывают только события за последний год.
Azure (https://azure.status.microsoft/en-us/status/history/) хранит пять лет. Cloudflare (https://www.cloudflarestatus.com/history?page=17) наиболее прозрачен; можно листать страницы назад на несколько лет.
«Смерть» публичного облака
В молодости я любил читать и рефакторить чужой код. Пока «Java Boy» не преподал урок: даже после того, как я починил утечку памяти, он почувствовал глубокий экзистенциальный кризис. Гневом он прикрывал собственную несостоятельность и возлагал вину за «поддержание стабильности платформы Kubernetes» на меня.
Я и сам не горел желанием за ним убирать. Просто частые алерты OOM kill меня раздражали. Из той истории я вынес философию нуля: рефакторинг с нулевой предельной выгодой никому не нужен.
Отсюда закон возрастания энтропии в софте: кодовую базу проекта со временем ожидает превращение в «свалку».
Кто-то спросил: какое это имеет отношение к «смерти» публичного облака?
Прямое. Потому что «индустриальный Ктулху» требует от компаний растущей прибыли. Поэтому для провайдеров публичного облака и их рядовых сотрудников необходимо «рассказывать новую историю роста» — в 2026 году эта история про AI.
Старый код просто гниёт. Менять его — нулевая предельная выгода.
И все сходятся в одном: не трогать чужой код, дать ему превратиться в свалку. И с кодом так, и с архитектурой. Даже когда сетевая топология — чистая сеть взаимных зависимостей, при сбое все одинаково без сервиса, и когда ответственность за простой распределена поровну, на тебе лично ответственности нет.
Ирония в том, что инженера по эксплуатации с нулём инцидентов за время работы, который «каждый день спит на работе», сочтут некомпетентным — потому что выглядит, будто он ничего не делает. Контринтуитивно: такого человека стоило бы держать как талисман компании — неизвестно, сколько он сделал раньше ради стабильности. Или ему просто повезло, и он заслуживает алтаря.
Лучшая эксплуатация — не эксплуатировать. Потому что доход от эксплуатации и карьерный риск совершенно несоизмеримы. Начальник не доплатит за удаление «вроде бы ненужной» настройки; но за удаление нужной настройки БД тебя обругают заказчики.
Провайдеры публичного облака забывают: сетевой эффект может их поднять и может больно опустить. Чем больше у них заказчиков, тем сильнее сетевая цепная реакция от одного простоя. Как сбой Alipay 4 декабря 2025, ~21:00–23:37 — уже шестой крупный инцидент экосистемы Alibaba в 2025 году.
Когда масштаб пользователей — сотни миллионов, каждую секунду кто-то платит. А бизнес продолжает требовать новые функции; в конце концов система не выдерживает.
И компенсация провайдеров публичного облака совершенно несоизмерима. Для чего-то вроде Alipay это максимум «вернуть разницу»; недобор считают подарком. Но потери госсектора и предприятий не поддаются оценке. Если твой бизнес на публичном облаке и облако легло — как ты объяснишь провайдеру свой ущерб?
«Моя система обрабатывает миллиарды транзакций в день; вы мне компенсируете пару миллиардов?»
Ущерб заказчика не квантифицируем, поэтому Alibaba Cloud обычно просто раздаёт ваучеры. Это капля в море. Никто не может толком учесть потерянное время, реальное влияние на бизнес и ценность этого времени.
Сетевой эффект принёс публичному облаку экспоненциальный рост выручки. Для крупных государственных и корпоративных пользователей антизависимость от одного публичного облака должна быть в повестке. Связать свою судьбу с одним облачным провайдером — нельзя справиться с внезапным риском.
Системы малой параллельности и высокой доступности
На этой основе я предлагаю «системы малой параллельности и высокой доступности»: избыточность хранилища для высокой доступности бизнеса.
Когда трафик распределён по избыточным системам, ты избегаешь пика трафика одного кластера при централизованном потоке и сокращаешь радиус распространения сбоя.
Простейший пример: при разрешении DNS направлять Гуандун на кластер Kubernetes Alibaba + Tencent в Южном Китае. Каждый кластер независим и крутит полную внутреннюю бизнес-систему. В худшем случае при сбое самого публичного облака недоступность не более 50%.
Одновременная недоступность обоих крайне маловероятна.
孤帆远影碧山尽,唯见长江天际流
Прощай, облачный сервис. Увидимся на Янцзы.
Ссылки
【1】
Сбой сервисов Cloudflare 18 ноября 2025
https://blog.cloudflare.com/zh-cn/18-november-2025-outage/
【2】
Невидимое влияние DNS на примере сбоя AWS: как DeepFlow быстро нашёл первопричину в хаосе
https://my.oschina.net/u/3681970/blog/18697034
【3】
Разбор и анализ сбоя Alibaba Cloud 2023-11-12
https://github.tiankonguse.com/blog/2023/11/29/aliyun-break.html
💬 讨论 / Discussion
对这篇文章有想法?欢迎在 GitHub 上发起讨论。
Have thoughts on this post? Start a discussion on GitHub.