我在2018年中的时候开始接触 kubernetes ,并主导过传统应用向容器化方向的转换工作。
结合落地过程中遇到的实际问题,以及相应的故障处理经验,我来讲一下要如何更好地管理TKE集群。
集群管理
其实使用TKE之前,应该先问自己一个问题。这个问题叫做准备好面对疾风了吗 ?Oh no,应该叫做你真的适合 kubernetes 吗?

一开始接触 kubernetes 的时候,我被它自动伸缩,应用自愈,快速迭代,版本回滚,负载均衡等特性深深吸引,但当我接触并使用一段时间之后,被应用性能监控,节点故障,网络诊断折磨得死去活来。
最有印象的是,当时有一个JAVA开发工程师这么质问我:“我的应用在本地和云服务器上面跑都没有问题,为什么容器化之后响应就变慢。这些都是你的问题。”
之后我特意花了点时间,长时间关注并监控这个JAVA应用,直到我找到 OOM kill 以及响应变慢的原因,并花了一个周六的时间,修复内存泄露这个代码问题之后,世界终于恢复了往日的和平。
是的,这不是 kubernetes 的问题,这也是 kubernetes 的问题。程序设计素有没有银弹这种说法。所谓的简便,不过是把复杂性转移到别的地方。应用的最终一致性,是靠各种各样的 Controller 调谐,而所谓的负载均衡,则是遍布所有节点的各种 IPtable 规则,应用的重启则是靠节点上勤劳的 kubelet 。
所以,如果你没有勇气应对容器化带来的全新挑战,又或者应用规模非常地小,迭代次数不频繁,那我还是不建议各位趟这波浑水。

“拿着一把锤子,看见什么都是钉子。”这是病,得治。而只有真正的勇士,才敢于直面惨淡的人生。
集群规划
凡事预则立,不预则废。关于集群的部署,我们的官方文档其实已经说得比较详细了,我觉得集群规划比较重要的地方在于容器运行时和网络插件的选择。
我个人认为,从业务前瞻性来讲,containerd 会比 docker 好一点,因为谷歌和 docker 公司利益不同。kubernetes 在一开始立项的时候就以 CRI 的形式确立了容器运行时的标准,而不是把 docker 直接拿来用,这个动作是有隐喻的。这个伏笔就是在 kubernetes 1.20 里面将放弃对 docker 的支持。
而网络插件,得结合平台和应用特性而定。以腾讯云为例,目前我们支持GlobalRouter 和 VPC-CNI。简单地说,VPC-CNI的网络性能会更好一些,但会受限于机器核心数,如果应用的特性以小型微服务(内存占用1G以内)为主,那么使用GlobalRouter 会合适一点。
除此以外,容器网络的CIDR也是一个痛点,如果CIDR设置的范围太小,那么可分配的pod/service IP过少,也会影响最终的应用规模。
灾备方案
曾经有一个美好的 namespace 放在我面前我没有珍惜,直到我误删了她的时候才知道一切都已太迟。如果上天能给我一次再来一次的机会,我真的希望那个时候的我脑子没有进水。

我还记得那次的事故,为了恢复整体业务的可用,连累了半个技术部加班到很晚。但在恢复营业的过程中,其实也发现了以前一些工作不到位的地方:比如给开发修改某个 namespace 内资源的权限,结果开发更新应用为了方便,直接修改YAML里面的ENV,但是后来又把配置忘了;比如对 kubernetes YAML没有备份等。
结合一整个应用的交付流程,我后来做了一个比较简便的方案:
- 对代码服务器的磁盘进行周期性备份
- 对kuber YAML 用kube-backup同步到 git 仓库
- 拉取镜像的账户只配置了
pull image权限 - 把生产级别的资源放到default namespace里面(因为这个默认
namespaces是不能删除的) - 关闭了开发的修改权限,配置全部走配置中心,并且移除了大部分的configmap
- 关闭了我自己的 admin 账号,分配了一个没有删除权限的
api-server证书
关于第5点是有争议的。我个人认为,当我们依赖某种技术的时候,应该考虑“反依赖性”。反依赖性是指如果这种技术过时,或者出现严重的问题时,我们的 plan B 是什么?
虽然 kubernetes 提供了热更新的一个机制,但是为了减轻 ETCD 的负担,也为了减少对 kubernetes 的依赖,我们把配置放到了 consul 那边。
上医治未病,下医治已病。希望大家不要像我这样,等到问题出现时,才想着怎么解决问题。
节点管理
TKE的节点资源规划其实是一个有点复杂的「费米估算」问题,合理地管理规划节点,有助于更好地降本增效。
节点配置,需要切合实际情况。像是计算密集型的应用,就要分配多一点CPU,而内存消耗性应用,我个人偏好4核32G的节点多一点。
对节点有特殊要求的服务可使用节点亲和性(Node Affinity)部署,以便调度到符合要求的节点。例如,让 MySQL 调度到高 IO 的机型以提升数据读写效率。
而GPU型节点一般是有特殊用途的,把它们跟普通节点一起向用户交付是不合适的。所以我一般建议用节点污点跟其他节点做隔离,确保特殊类型的节点不会运行不符合预期的容器。
1
kubectl taint node $no just-for-gpu-application=true:NoExecute
1
2
3
4
5
6
7
tolerations:
- key: "just-for-gpu-application"
operator: "Exists"
effect: "NoSchedule"
- key: "just-for-gpu-application"
operator: "Exists"
effect: "NoExecute"
我个人其实不建议在 kubernetes 集群里面加入小配置的节点(比如1核2G这样的配置),因为这样会损失应用伸缩的“弹性”,比如一个应用一开始给了0.7核1.5G,但运行一段时间之后发现要2核4G的配置,这样重新调度就只能放弃原有节点。而且这种低配置的节点其实也不是很符合分布式系统的设计理念——靠资源的冗余实现高可用性。
那么节点的配置是不是越高越好呢?
这个问题其实没有一个标准的答案。但我多次遇过因为节点 docker hang 或者 Not Ready ,甚至是节点负载过高,而导致的整体节点故障问题。这会引发节点上面所有应用的雪崩和不可用。
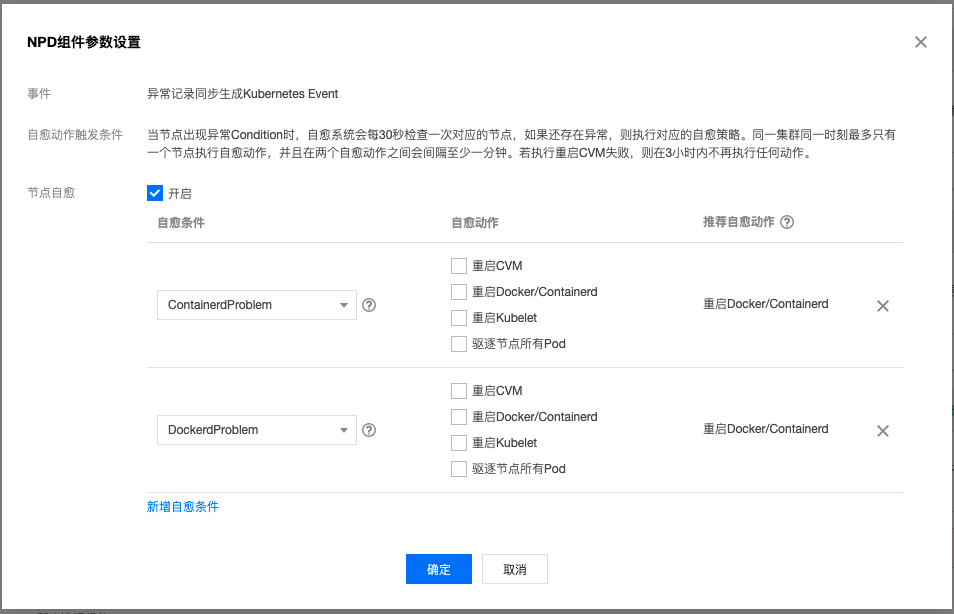
针对单点节点故障而导致的问题,除了在云监控上面建立相应的告警策略外, 我们在社区版本的基础上,对NPD做了增强。支持节点自愈(具体见《使用 TKE NPDPlus 插件增强节点的故障自愈能力》),用户可以选择重启容器运行时甚至重启CVM。
除此以外,我们TKE还支持使用置放群组从物理层面实现容灾,从云服务器底层硬件层面,利用反亲和性将 Pod 打散到不同节点上。
业务管理
kubernetes 这套 DevOps 系统对运维和研发都是一种挑战。研发要适应 pod 这种朝生夕死的架构,拥抱应用容器化带来的变化。
易失性
只是一切都将逝去。
在我的世界里,这或许是唯一可以视为真理的一句话。 《人间失格》
易失性有几个理解。首先,研发要适应容器的IP是变动的,其次,文件系统也是变动的。以往当代码部署在CVM上面的时候,我们可以在服务器上安装各种调试工具,但是在容器的环境,就会面临两难的选择:是把调试工具打包进镜像,还是用 kubectl exec 进入容器安装。
如果把工具打包进容器,那么就会让镜像带上一些业务无关的内容,导致镜像更大,发布慢一点;而如果把调试工具放在容器里面安装,则会面临每次更新/重启都需要做大量重复工作。
这里我同样不会给出标准答案,但我会告诉大家在另外几个维度,业务的管理可以怎么去做。
可观察性
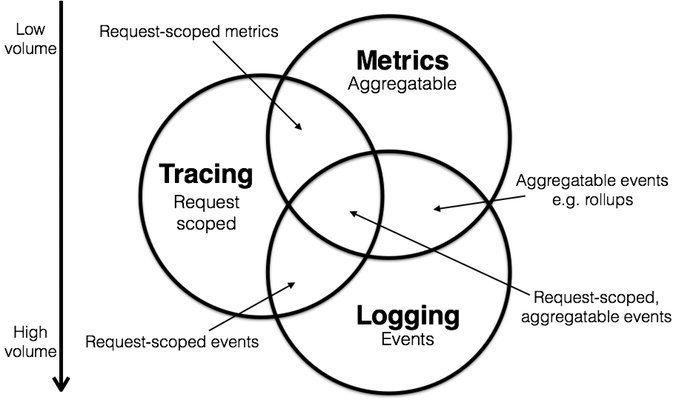
目前业界对可观察性的看法是将其分为
- Metrics
- Tracing
- Logging
这几部分。在这一方面,我们腾讯云基于 Prometheus 做了一套云原生监控的方案,以及日志采集 , 事件存储。这几套方案涵盖了指标监控,日志采集,事件存储和监控告警等各个方面。
而从 Tracing 角度方面考虑,分布式服务的跟踪监测我觉得还可以再细分为非侵入式和侵入式的方案。侵入式的方案指的是修改代码,比如在请求的链路里面加入特定请求头,request header;非侵入式方案则是现在很流行的 Service Mesh方案,让业务更加注重于业务,而让流量管控交给 sidecar 。由于篇幅限制,这里就不过多展开了。
隔离性
资源隔离性
资源的隔离性,其实也能继续细分为同集群内资源的隔离和多租户的隔离。在之前的章节中,我已经提到了用节点污点隔离普通节点和GPU节点,这其实就是一种资源隔离的方式。
而多租户,最简单的实现莫过于一个用户一个 namespace ,然后用 LimitRange 限制。
资源的隔离性不仅存在于集群内,也存在于集群外。有时候我们会在同一个 VPC 或者跨 VPC 建集群,以实现彻底的资源隔离性,但是这种做法,也会产生跨云通讯的新问题(在VPC层面,我们支持通过对等连接和云联网通信)。这对整个微服务架构,会是一种新的挑战。
网络隔离性
理解网络隔离性,要反过来先理解网络连通性。以 Flannel 的 VXLAN 模式为例,采用这个模式的 kubernetes 集群节点之间是互联的。而且实际上,跨 namespace 的 service 也是互联的。
这里也许有人有个疑问:不是说 kubernetes 是基于 namespace 做的资源隔离吗?为什么说跨 namespace 的访问是互联的?
这里就不得不提到 kubernetes 注入的这个 /etc/resolv.conf 文件,以 default 下面随便一个未修改过网络配置的 pod 为例:
1
2
3
4
cat /etc/resolv.conf
nameserver <kube-dns-vip>
search default.svc.cluster.local svc.cluster.local cluster.local localdomain
options ndots:5
这个配置的意思是五级域名以下走 coreDNS ,优先按照 search 顺序补全。比如解析百度是这样:
1
2
3
4
5
6
7
sh-4.2# host -v baidu.com
Trying "baidu.com.<namespace>.svc.cluster.local"
Trying "baidu.com.svc.cluster.local"
Trying "baidu.com.cluster.local"
Trying "baidu.com.localdomain"
Trying "baidu.com"
......
这里其实就可以看出端倪。比如我们在 default 和 kube-system 下面同时建立了一个名为 tke-six-six-six 的服务,在 default 下面之所以访问 six 不会跳到 kube-system 定义的服务,是因为一开始尝试解析的就是 tke-six-six-six.default.svc.cluster.local ,而如果直接访问 tke-six-six-six.kube-system.svc.cluster.local ,也是可以的。所谓的隔离只是在域名解析那里做了手脚。
网络的隔离性,在多租户环境下显得尤为重要。我们不能保证来往的流量都是合法的,那就先假定所有的流量都是非法的,只让符合要求的流量接入应用。如果不用 istio 的话,其实官方也基于ip,namespaceSelector和podSelector做了 Network Policy。
自愈性
这里再次套用分布式系统的第一性原理——通过资源的冗余实现系统的可用。一般为了规避单一节点的不可用,我们会建议用户对应用设置2以上的副本并设置 podAntiAffinity 。
1
2
3
4
5
6
7
8
9
10
11
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- my-pipi-server
topologyKey: kubernetes.io/hostname
weight: 100
除此以外,一般我们会建议用户加上以下配置
- readinessProbe(就绪检查)
- livenessProbe(健康检查)
- preStop hook
就绪检查和健康检查的重要性自不必说,preStop hook 可以设置 sleep 一小段的时间,因为 kube-proxy 更新节点转发规则的动作并不是及时的,给 Pod 中的 container 添加 preStop hook,使 Pod 真正销毁前先 sleep 等待一段时间,留出时间给 Endpoint controller 和 kube-proxy 更新 Endpoint 和转发规则。
注意 terminationGracePeriodSeconds 的默认设置是30秒。如果preStop hook 设置的时间超过30秒,那么 terminationGracePeriodSeconds 的值也要做相应改变。
总结
纸上得来终觉浅,绝知此事要躬行。容器化对运维和开发都有新的考验,切不可掉以轻心。
希望大家不管是运维也好,开发也罢,能在运维中提炼管理的技巧,在开发中解锁新的 翻车编程 招式。

没有问题才是最大的问题,没有答案,就自己找答案!
参考链接
[1] Introducing Container Runtime Interface (CRI) in Kubernetes https://kubernetes.io/blog/2016/12/container-runtime-interface-cri-in-kubernetes/
[2] K8s宣布弃用Docker,千万别慌! https://cloud.tencent.com/developer/article/1758588
[3] 解读:云原生下的可观察性发展方向 https://cloudnative.to/blog/cloud-native-observability/
[4] 十分钟漫谈容器网络方案 01—Flannel https://www.infoq.cn/article/rnbqhui1wipzj6bjiwet
I started working with kubernetes in mid-2018 and led the transformation of traditional applications toward containerization.
Combining the actual problems encountered during implementation and the corresponding troubleshooting experience, let me talk about how to better manage TKE clusters.
Cluster Management
Actually, before using TKE, you should ask yourself a question. This question is called are you ready to face the storm? Oh no, it should be: are you really suitable for kubernetes?
When I first encountered kubernetes, I was deeply attracted by its features like auto-scaling, application self-healing, rapid iteration, version rollback, load balancing, etc. But after using it for a while, I was tormented to death by application performance monitoring, node failures, and network diagnostics.
What impressed me most was when a JAVA developer questioned me like this: “My application runs fine locally and on cloud servers, so why does it slow down after containerization? This is all your problem.”
Afterwards, I deliberately spent some time monitoring this JAVA application for a long time, until I found the cause of OOM kills and slow responses, and spent a Saturday fixing the memory leak—this code problem—before the world finally returned to its former peace.
Yes, this is not a kubernetes problem, and this is also a kubernetes problem. Software design has always had the saying “no silver bullet”. The so-called convenience is just shifting complexity elsewhere. The eventual consistency of applications relies on various Controller reconciliations, while the so-called load balancing is various iptable rules spread across all nodes, and application restarts rely on the hardworking kubelet on nodes.
So, if you don’t have the courage to face the new challenges brought by containerization, or if your application scale is very small and iteration frequency is low, I still don’t recommend you wade into these muddy waters.
“When you have a hammer, everything looks like a nail.” This is a disease that needs treatment. Only true warriors dare to face the bleak reality of life.
Cluster Planning
Forewarned is forearmed. Regarding cluster deployment, our official documentation is actually quite detailed. I think the important aspects of cluster planning lie in the choice of container runtime and network plugin.
Personally, I think from a business perspective, containerd is slightly better than docker because Google and Docker Inc. have different interests. kubernetes established the container runtime standard in the form of CRI from the start, rather than directly using docker. This action has implications. The foreshadowing is that kubernetes 1.20 will drop support for docker.
As for network plugins, it depends on the platform and application characteristics. Taking Tencent Cloud as an example, we currently support GlobalRouter and VPC-CNI. Simply put, VPC-CNI has better network performance, but is limited by the number of machine cores. If applications are mainly small microservices (memory usage within 1G), then using GlobalRouter would be more appropriate.
In addition, the CIDR of the container network is also a pain point. If the CIDR range is set too small, there will be too few allocatable pod/service IPs, which will also affect the final application scale.
Disaster Recovery Plan
Once there was a beautiful namespace placed before me that I didn’t cherish, until I accidentally deleted her and realized everything was too late. If heaven could give me another chance, I really wish my brain hadn’t been waterlogged at that time.
I still remember that incident. To restore overall business availability, half the tech department had to work overtime until very late. But during the recovery process, we actually discovered some areas where previous work was inadequate: for example, giving developers permission to modify resources in a certain namespace, but developers updated applications for convenience by directly modifying ENV in YAML, then forgot the configuration later; for example, not backing up kubernetes YAML, etc.
Combining the entire application delivery process, I later created a relatively simple solution:
- Periodic backup of code server disks
- Sync kubernetes YAML to git repository using kube-backup
- Image pull accounts only have
pull imagepermissions - Put production-level resources in the default namespace (because this default
namespacecannot be deleted) - Disabled developer modification permissions, all configurations go through the configuration center, and removed most configmaps
- Disabled my own admin account, allocated an
api-servercertificate without delete permissions
Point 5 is controversial. Personally, I think when we depend on a certain technology, we should consider “anti-dependency”. Anti-dependency means: if this technology becomes obsolete or has serious problems, what is our plan B?
Although kubernetes provides a hot update mechanism, to reduce the burden on ETCD and reduce dependence on kubernetes, we put configurations in consul.
The best doctor treats before illness, the worst doctor treats after illness. I hope everyone doesn’t wait like me until problems appear before thinking about how to solve them.
Node Management
TKE node resource planning is actually a somewhat complex “Fermi estimation” problem. Properly managing and planning nodes helps better reduce costs and increase efficiency.
Node configuration needs to match actual situations. For compute-intensive applications, allocate more CPU, while for memory-consuming applications, I personally prefer 4-core 32G nodes more.
Services with special node requirements can use Node Affinity for deployment to schedule to nodes that meet requirements. For example, schedule MySQL to high IO models to improve data read/write efficiency.
GPU-type nodes generally have special purposes, and it’s inappropriate to deliver them together with regular nodes to users. So I generally recommend using node taints to isolate them from other nodes, ensuring special-type nodes don’t run containers that don’t meet expectations.
1
kubectl taint node $no just-for-gpu-application=true:NoExecute
1
2
3
4
5
6
7
tolerations:
- key: "just-for-gpu-application"
operator: "Exists"
effect: "NoSchedule"
- key: "just-for-gpu-application"
operator: "Exists"
effect: "NoExecute"
I personally don’t recommend adding small-configuration nodes (like 1-core 2G) to kubernetes clusters, because this loses the “elasticity” of application scaling. For example, an application initially gets 0.7 cores 1.5G, but after running for a while, it’s found to need 2 cores 4G configuration. Rescheduling can only abandon the original node. Moreover, such low-configuration nodes don’t really fit the design philosophy of distributed systems—achieving high availability through resource redundancy.
So, is higher node configuration always better?
This question actually has no standard answer. But I’ve encountered many times overall node failures caused by node docker hang or Not Ready, or even excessive node load. This triggers avalanches and unavailability of all applications on the node.
For problems caused by single-point node failures, in addition to establishing corresponding alert policies on cloud monitoring, we enhanced NPD based on the community version. It supports node self-healing (see “Using TKE NPDPlus Plugin to Enhance Node Fault Self-Healing Capability”). Users can choose to restart the container runtime or even restart CVM.
In addition, our TKE also supports using placement groups to achieve disaster recovery at the physical level, using anti-affinity at the cloud server underlying hardware level to scatter Pods across different nodes.
Business Management
The kubernetes DevOps system is a challenge for both operations and development. Development needs to adapt to the pod architecture of ephemeral existence, embracing changes brought by application containerization.
Volatility
Everything will pass.
In my world, this might be the only sentence that can be considered truth. 《No Longer Human》
Volatility has several meanings. First, development needs to adapt to the fact that container IPs are variable. Second, the file system is also variable. Previously, when code was deployed on CVM, we could install various debugging tools on the server, but in a container environment, we face a dilemma: should we package debugging tools into the image, or use kubectl exec to enter the container and install them?
If we package tools into containers, the image will include some business-unrelated content, making the image larger and deployment slower. If we install debugging tools in containers, we face a lot of repetitive work every time we update/restart.
I won’t give a standard answer here either, but I’ll tell you how business management can be done in other dimensions.
Observability
Currently, the industry’s view of observability is to divide it into:
- Metrics
- Tracing
- Logging
These parts. In this regard, we at Tencent Cloud have built a cloud-native monitoring solution based on Prometheus, as well as log collection and event storage. These solutions cover metrics monitoring, log collection, event storage, monitoring alerts, and other aspects.
From a Tracing perspective, distributed service tracking and monitoring can be further subdivided into non-invasive and invasive solutions. Invasive solutions refer to modifying code, such as adding specific request headers in the request chain; non-invasive solutions are the now-popular Service Mesh approach, letting business focus more on business, while letting traffic control be handled by sidecars. Due to space limitations, I won’t expand on this here.
Isolation
Resource Isolation
Resource isolation can be further subdivided into resource isolation within the same cluster and multi-tenant isolation. In previous chapters, I mentioned using node taints to isolate regular nodes and GPU nodes, which is actually a form of resource isolation.
For multi-tenancy, the simplest implementation is one user per namespace, then use LimitRange to limit.
Resource isolation exists not only within clusters but also outside clusters. Sometimes we build clusters in the same VPC or across VPCs to achieve complete resource isolation, but this approach also creates new problems with cross-cloud communication (at the VPC level, we support communication through peering connections and cloud networking). This will be a new challenge for the entire microservices architecture.
Network Isolation
To understand network isolation, we must first understand network connectivity in reverse. Taking Flannel’s VXLAN mode as an example, kubernetes cluster nodes using this mode are interconnected. And actually, services across namespaces are also interconnected.
Some might have a question here: isn’t kubernetes based on namespace for resource isolation? Why is cross-namespace access interconnected?
Here we have to mention the /etc/resolv.conf file that kubernetes injects. Taking any unmodified network configuration pod under default as an example:
1
2
3
4
cat /etc/resolv.conf
nameserver <kube-dns-vip>
search default.svc.cluster.local svc.cluster.local cluster.local localdomain
options ndots:5
This configuration means domains with fewer than five levels go through coreDNS, prioritized according to the search order. For example, resolving baidu.com goes like this:
1
2
3
4
5
6
7
sh-4.2# host -v baidu.com
Trying "baidu.com.<namespace>.svc.cluster.local"
Trying "baidu.com.svc.cluster.local"
Trying "baidu.com.cluster.local"
Trying "baidu.com.localdomain"
Trying "baidu.com"
......
Here we can see the clue. For example, if we create a service named tke-six-six-six under both default and kube-system, the reason accessing six under default doesn’t jump to the service defined in kube-system is because it first tries to resolve tke-six-six-six.default.svc.cluster.local. But if we directly access tke-six-six-six.kube-system.svc.cluster.local, it’s also possible. The so-called isolation is just manipulation at the domain resolution level.
Network isolation is particularly important in multi-tenant environments. We can’t guarantee that all incoming and outgoing traffic is legitimate, so we first assume all traffic is illegitimate, only allowing traffic that meets requirements to access applications. If not using istio, the official also provides Network Policy based on ip, namespaceSelector, and podSelector.
Self-Healing
Here I’ll apply the first principle of distributed systems again—achieving system availability through resource redundancy. Generally, to avoid single-node unavailability, we recommend users set applications to 2 or more replicas and set podAntiAffinity.
1
2
3
4
5
6
7
8
9
10
11
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- my-pipi-server
topologyKey: kubernetes.io/hostname
weight: 100
In addition, we generally recommend users add the following configurations:
- readinessProbe (readiness check)
- livenessProbe (health check)
- preStop hook
The importance of readiness checks and health checks goes without saying. preStop hook can set a short sleep time, because kube-proxy’s action of updating node forwarding rules is not immediate. Adding a preStop hook to containers in Pods makes Pods sleep and wait for a period before truly being destroyed, giving time for Endpoint controller and kube-proxy to update Endpoints and forwarding rules.
Note that the default setting of terminationGracePeriodSeconds is 30 seconds. If the preStop hook time exceeds 30 seconds, the value of terminationGracePeriodSeconds should also be changed accordingly.
Summary
What is learned from books is shallow; true knowledge comes from practice. Containerization brings new tests for both operations and development, so don’t take it lightly.
I hope everyone, whether in operations or development, can extract management skills from operations and unlock new overturn programming moves in development.
No problems are the biggest problem. If there’s no answer, find the answer yourself!
References
[1] Introducing Container Runtime Interface (CRI) in Kubernetes https://kubernetes.io/blog/2016/12/container-runtime-interface-cri-in-kubernetes/
[2] K8s宣布弃用Docker,千万别慌! https://cloud.tencent.com/developer/article/1758588
[3] 解读:云原生下的可观察性发展方向 https://cloudnative.to/blog/cloud-native-observability/
[4] 十分钟漫谈容器网络方案 01—Flannel https://www.infoq.cn/article/rnbqhui1wipzj6bjiwet
2018年半ばにkubernetesに触れ始め、従来のアプリケーションのコンテナ化への変換を主導しました。
実装中に遭遇した実際の問題と、対応するトラブルシューティングの経験を組み合わせて、TKEクラスターをより適切に管理する方法について説明します。
クラスター管理
実際、TKEを使用する前に、自分に質問すべきです。この質問は嵐に直面する準備はできていますか?いや、それは:あなたは本当にkubernetesに適していますか?
kubernetesに初めて遭遇したとき、自動スケーリング、アプリケーションの自己回復、迅速な反復、バージョンロールバック、負荷分散などの機能に深く魅了されました。しかし、しばらく使用した後、アプリケーションパフォーマンス監視、ノード障害、ネットワーク診断に苦しめられました。
最も印象的だったのは、JAVA開発者がこのように私を問い詰めたときでした:「私のアプリケーションはローカルとクラウドサーバーで正常に動作していますが、コンテナ化後に遅くなるのはなぜですか?これはすべてあなたの問題です。」
その後、意図的に時間を費やし、このJAVAアプリケーションを長時間監視し、OOM killと応答が遅い原因を見つけ、土曜日を費やしてメモリリーク—このコード問題—を修正し、世界がようやく以前の平和に戻りました。
はい、これはkubernetesの問題ではなく、これもkubernetesの問題です。ソフトウェア設計には常に「銀の弾丸はない」という言葉があります。いわゆる便利さは、複雑さを別の場所に移すだけです。アプリケーションの最終的な一貫性は、さまざまなControllerの調整に依存し、いわゆる負荷分散はすべてのノードに広がるさまざまなiptableルールであり、アプリケーションの再起動はノード上の勤勉なkubeletに依存します。
したがって、コンテナ化がもたらす新しい課題に直面する勇気がない場合、またはアプリケーションの規模が非常に小さく、反復頻度が低い場合、これらの泥だらけの水域に足を踏み入れることはお勧めしません。
「ハンマーを持っていると、すべてが釘のように見える。」これは治療が必要な病気です。真の戦士だけが人生の厳しい現実に直面する勇気があります。
クラスター計画
備えあれば憂いなし。クラスターのデプロイメントに関して、私たちの公式ドキュメントは実際にはかなり詳細です。クラスター計画の重要な側面は、コンテナランタイムとネットワークプラグインの選択にあります。
個人的には、ビジネスの観点から、containerdはdockerよりわずかに優れていると思います。GoogleとDocker Inc.は異なる利益を持っているためです。kubernetesは最初からCRIの形式でコンテナランタイム標準を確立し、dockerを直接使用するのではなく、このアクションには意味があります。伏線は、kubernetes 1.20がdockerのサポートを廃止することです。
ネットワークプラグインについては、プラットフォームとアプリケーションの特性によって異なります。Tencent Cloudを例にとると、現在GlobalRouterとVPC-CNIをサポートしています。簡単に言えば、VPC-CNIはより優れたネットワークパフォーマンスを持っていますが、マシンコア数によって制限されます。アプリケーションが主に小さなマイクロサービス(メモリ使用量1G以内)である場合、GlobalRouterを使用する方が適切です。
さらに、コンテナネットワークのCIDRも痛みのポイントです。CIDR範囲が小さすぎる場合、割り当て可能なpod/service IPが少なすぎ、最終的なアプリケーション規模にも影響します。
災害復旧計画
かつて、私の前に美しいnamespaceが置かれていましたが、大切にしませんでした。誤って削除して、すべてが手遅れであることに気づくまで。天がもう一度チャンスを与えてくれるなら、その時私の脳が水浸しになっていなかったことを本当に願います。
その事件を今でも覚えています。全体的なビジネスの可用性を回復するために、技術部門の半分が非常に遅くまで残業しなければなりませんでした。しかし、回復プロセス中に、以前の作業が不十分だった領域を実際に発見しました:例えば、開発者に特定のnamespace内のリソースを変更する権限を与えたが、開発者が便利のためにYAMLのENVを直接変更してアプリケーションを更新し、後で設定を忘れた;例えば、kubernetes YAMLをバックアップしなかったなど。
アプリケーション配信プロセス全体を組み合わせて、後で比較的簡単なソリューションを作成しました:
- コードサーバーディスクの定期的なバックアップ
- kube-backupを使用してkubernetes YAMLをgitリポジトリに同期
- イメージプルアカウントには
pull image権限のみ - 本番レベルのリソースをデフォルトの名前空間に配置(このデフォルトの
namespaceは削除できないため) - 開発者の変更権限を無効にし、すべての設定を設定センター経由で行い、ほとんどのconfigmapを削除
- 自分のadminアカウントを無効にし、削除権限のない
api-server証明書を割り当て
ポイント5は議論の余地があります。個人的には、特定のテクノロジーに依存する場合、「反依存性」を考慮すべきだと思います。反依存性とは:このテクノロジーが時代遅れになったり、深刻な問題が発生した場合、私たちのプランBは何ですか?
kubernetesはホットアップデートメカニズムを提供していますが、ETCDの負担を軽減し、kubernetesへの依存を減らすために、設定をconsulに配置しました。
最高の医者は病気の前に治療し、最悪の医者は病気の後に治療します。私のように問題が現れるまで待ってから、解決方法を考えることがないように願います。
ノード管理
TKEノードリソース計画は、実際にはやや複雑な「フェルミ推定」問題です。ノードを適切に管理および計画することで、コスト削減と効率向上に役立ちます。
ノード設定は、実際の状況に合わせる必要があります。計算集約型アプリケーションの場合、より多くのCPUを割り当て、メモリ消費型アプリケーションの場合、個人的には4コア32Gノードを好みます。
特別なノード要件を持つサービスは、Node Affinityを使用してデプロイし、要件を満たすノードにスケジュールできます。例えば、データの読み書き効率を向上させるために、MySQLを高IOモデルにスケジュールします。
GPU型ノードは一般的に特別な目的があり、通常のノードと一緒にユーザーに提供するのは適切ではありません。したがって、一般的にはノードのtaintを使用して他のノードから分離し、特別なタイプのノードが期待に合わないコンテナを実行しないようにすることをお勧めします。
1
kubectl taint node $no just-for-gpu-application=true:NoExecute
1
2
3
4
5
6
7
tolerations:
- key: "just-for-gpu-application"
operator: "Exists"
effect: "NoSchedule"
- key: "just-for-gpu-application"
operator: "Exists"
effect: "NoExecute"
個人的には、kubernetesクラスターに小さな設定のノード(1コア2Gなど)を追加することはお勧めしません。これはアプリケーションスケーリングの「弾力性」を失うためです。例えば、アプリケーションは最初に0.7コア1.5Gを取得しますが、しばらく実行した後、2コア4G設定が必要であることがわかります。再スケジューリングは元のノードを放棄するしかありません。さらに、このような低設定のノードは、分散システムの設計哲学—リソースの冗長性による高可用性の実現—にあまり適合していません。
では、ノード設定は常に高いほど良いのでしょうか?
この質問には実際には標準的な答えがありません。しかし、ノードのdocker hangやNot Ready、さらには過度のノード負荷によって引き起こされる全体的なノード障害に何度も遭遇しました。これはノード上のすべてのアプリケーションの雪崩と利用不可を引き起こします。
単一ポイントノード障害によって引き起こされる問題については、クラウド監視に適切なアラートポリシーを確立することに加えて、コミュニティバージョンに基づいてNPDを強化しました。ノードの自己回復をサポートします(「TKE NPDPlusプラグインを使用してノードの障害自己回復能力を強化」を参照)。ユーザーはコンテナランタイムを再起動するか、CVMを再起動することを選択できます。
さらに、TKEは配置グループを使用して物理レベルで災害復旧を実現することもサポートしており、クラウドサーバーの基盤ハードウェアレベルで反親和性を使用して、Podsを異なるノードに分散させます。
ビジネス管理
kubernetesのDevOpsシステムは、運用と開発の両方にとって課題です。開発は一時的な存在のpodアーキテクチャに適応し、アプリケーションコンテナ化がもたらす変化を受け入れる必要があります。
揮発性
すべてが過ぎ去る。
私の世界では、これが真実と見なせる唯一の文かもしれません。 《人間失格》
揮発性にはいくつかの意味があります。まず、開発はコンテナIPが可変であるという事実に適応する必要があります。第二に、ファイルシステムも可変です。以前、コードがCVMにデプロイされたとき、サーバーにさまざまなデバッグツールをインストールできましたが、コンテナ環境では、ジレンマに直面します:デバッグツールをイメージにパッケージ化するか、kubectl execを使用してコンテナに入り、インストールするか?
ツールをコンテナにパッケージ化すると、イメージにビジネスに関連しないコンテンツが含まれ、イメージが大きくなり、デプロイが遅くなります。コンテナにデバッグツールをインストールすると、更新/再起動のたびに多くの繰り返し作業に直面します。
ここでも標準的な答えは提供しませんが、他の次元でビジネス管理をどのように行うことができるかを説明します。
可観測性
現在、業界の可観測性の見解は、それを以下に分割することです:
- Metrics
- Tracing
- Logging
これらの部分。この点で、Tencent CloudはPrometheusに基づいてクラウドネイティブ監視ソリューション、およびログ収集とイベントストレージを構築しました。これらのソリューションは、メトリクス監視、ログ収集、イベントストレージ、監視アラートなどの側面をカバーしています。
Tracingの観点から、分散サービスの追跡と監視は、非侵入的および侵入的ソリューションにさらに細分化できます。侵入的ソリューションは、コードを変更することを指し、リクエストチェーンに特定のリクエストヘッダーを追加するなどです。非侵入的ソリューションは、現在人気のService Meshアプローチで、ビジネスをビジネスにより集中させ、トラフィック制御をsidecarに任せます。スペースの制限により、ここではこれ以上展開しません。
分離
リソース分離
リソース分離は、同じクラスター内のリソース分離とマルチテナント分離にさらに細分化できます。前の章で、ノードのtaintを使用して通常のノードとGPUノードを分離することに言及しましたが、これは実際にはリソース分離の形式です。
マルチテナンシーについては、最も簡単な実装は、ユーザーごとに1つのnamespace、次にLimitRangeを使用して制限することです。
リソース分離は、クラスター内だけでなく、クラスター外にも存在します。完全なリソース分離を実現するために、同じVPCまたはVPC間でクラスターを構築することがありますが、このアプローチは、クラウド間通信の新しい問題も生み出します(VPCレベルでは、ピアリング接続とクラウドネットワーキングを通じた通信をサポートしています)。これは、マイクロサービスアーキテクチャ全体にとって新しい課題となります。
ネットワーク分離
ネットワーク分離を理解するには、まず逆にネットワーク接続性を理解する必要があります。FlannelのVXLANモードを例にとると、このモードを使用するkubernetesクラスターノードは相互接続されています。そして実際、namespaces間のservicesも相互接続されています。
ここで疑問を持つ人もいるかもしれません:kubernetesはnamespaceに基づいてリソース分離を行っているのではないですか?なぜnamespace間のアクセスが相互接続されているのですか?
ここで、kubernetesが注入する/etc/resolv.confファイルについて言及する必要があります。defaultの下で変更されていないネットワーク設定のpodを例にとると:
1
2
3
4
cat /etc/resolv.conf
nameserver <kube-dns-vip>
search default.svc.cluster.local svc.cluster.local cluster.local localdomain
options ndots:5
この設定は、5レベル未満のドメインがcoreDNSを通過し、search順序に従って優先順位が付けられることを意味します。例えば、baidu.comの解決は次のようになります:
1
2
3
4
5
6
7
sh-4.2# host -v baidu.com
Trying "baidu.com.<namespace>.svc.cluster.local"
Trying "baidu.com.svc.cluster.local"
Trying "baidu.com.cluster.local"
Trying "baidu.com.localdomain"
Trying "baidu.com"
......
ここで手がかりを見ることができます。例えば、defaultとkube-systemの下にtke-six-six-sixという名前のサービスを作成した場合、defaultの下でsixにアクセスしてもkube-systemで定義されたサービスにジャンプしない理由は、最初にtke-six-six-six.default.svc.cluster.localを解決しようとするためです。しかし、tke-six-six-six.kube-system.svc.cluster.localに直接アクセスすることも可能です。いわゆる分離は、ドメイン解決レベルでの操作にすぎません。
ネットワーク分離は、マルチテナント環境で特に重要です。すべての入出力トラフィックが正当であることを保証できないため、まずすべてのトラフィックが不正であると仮定し、要件を満たすトラフィックのみがアプリケーションにアクセスできるようにします。istioを使用しない場合、公式はip、namespaceSelector、podSelectorに基づいてNetwork Policyも提供しています。
自己回復
ここで、分散システムの第一原理を再度適用します—リソースの冗長性によるシステム可用性の実現。一般的に、単一ノードの利用不可を回避するために、ユーザーにアプリケーションを2つ以上のレプリカに設定し、podAntiAffinityを設定することをお勧めします。
1
2
3
4
5
6
7
8
9
10
11
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- my-pipi-server
topologyKey: kubernetes.io/hostname
weight: 100
さらに、一般的にユーザーに以下の設定を追加することをお勧めします:
- readinessProbe(準備チェック)
- livenessProbe(ヘルスチェック)
- preStop hook
準備チェックとヘルスチェックの重要性は言うまでもありません。preStop hookは短いスリープ時間を設定できます。kube-proxyのノード転送ルールの更新アクションは即座ではないためです。PodsのコンテナにpreStop hookを追加すると、Podsは実際に破壊される前にスリープして待機し、Endpoint controllerとkube-proxyがEndpointsと転送ルールを更新する時間を提供します。
terminationGracePeriodSecondsのデフォルト設定は30秒であることに注意してください。preStop hookの時間が30秒を超える場合、terminationGracePeriodSecondsの値もそれに応じて変更する必要があります。
まとめ
本から学んだことは浅い;真の知識は実践から来ます。コンテナ化は運用と開発の両方に新しいテストをもたらすため、軽視しないでください。
運用でも開発でも、運用から管理スキルを抽出し、開発で新しい転覆プログラミングの動きを解き放つことができることを願います。
問題がないことが最大の問題です。答えがない場合は、自分で答えを見つけてください!
参考リンク
[1] Introducing Container Runtime Interface (CRI) in Kubernetes https://kubernetes.io/blog/2016/12/container-runtime-interface-cri-in-kubernetes/
[2] K8s宣布弃用Docker,千万别慌! https://cloud.tencent.com/developer/article/1758588
[3] 解读:云原生下的可观察性发展方向 https://cloudnative.to/blog/cloud-native-observability/
[4] 十分钟漫谈容器网络方案 01—Flannel https://www.infoq.cn/article/rnbqhui1wipzj6bjiwet
Я начал работать с kubernetes в середине 2018 года и возглавил преобразование традиционных приложений в сторону контейнеризации.
Объединяя реальные проблемы, с которыми столкнулись во время внедрения, и соответствующий опыт устранения неполадок, позвольте мне рассказать о том, как лучше управлять кластерами TKE.
Управление кластером
На самом деле, перед использованием TKE вы должны задать себе вопрос. Этот вопрос называется готовы ли вы столкнуться со штормом? О нет, это должно быть: действительно ли вы подходите для kubernetes?
Когда я впервые столкнулся с kubernetes, я был глубоко привлечён его функциями, такими как автоматическое масштабирование, самовосстановление приложений, быстрая итерация, откат версий, балансировка нагрузки и т.д. Но после использования в течение некоторого времени я был замучен до смерти мониторингом производительности приложений, сбоями узлов и диагностикой сети.
Больше всего меня впечатлило, когда разработчик JAVA задал мне такой вопрос: “Моё приложение отлично работает локально и на облачных серверах, так почему оно замедляется после контейнеризации? Это вся ваша проблема.”
После этого я намеренно потратил некоторое время, долго наблюдая за этим JAVA-приложением, пока не нашёл причину OOM kills и медленных ответов, и потратил субботу на исправление утечки памяти—этой проблемы кода—прежде чем мир наконец вернулся к прежнему спокойствию.
Да, это не проблема kubernetes, и это также проблема kubernetes. В проектировании программного обеспечения всегда была поговорка “нет серебряной пули”. Так называемое удобство — это просто перенос сложности в другое место. Финальная согласованность приложений зависит от различных согласований Controller, в то время как так называемая балансировка нагрузки — это различные правила iptable, разбросанные по всем узлам, а перезапуски приложений зависят от трудолюбивого kubelet на узлах.
Итак, если у вас нет смелости столкнуться с новыми вызовами, принесёнными контейнеризацией, или если масштаб вашего приложения очень мал, а частота итераций низка, я всё ещё не рекомендую вам вступать в эти мутные воды.
“Когда у вас есть молоток, всё выглядит как гвоздь.” Это болезнь, требующая лечения. Только настоящие воины осмеливаются столкнуться с мрачной реальностью жизни.
Планирование кластера
Предупреждён — значит вооружён. Что касается развёртывания кластера, наша официальная документация на самом деле довольно подробна. Я думаю, что важные аспекты планирования кластера заключаются в выборе среды выполнения контейнеров и сетевого плагина.
Лично я думаю, что с точки зрения бизнеса containerd немного лучше, чем docker, потому что у Google и Docker Inc. разные интересы. kubernetes установил стандарт среды выполнения контейнеров в форме CRI с самого начала, а не напрямую используя docker. Это действие имеет значение. Предзнаменование в том, что kubernetes 1.20 откажется от поддержки docker.
Что касается сетевых плагинов, это зависит от платформы и характеристик приложения. В качестве примера возьмём Tencent Cloud, мы в настоящее время поддерживаем GlobalRouter и VPC-CNI. Проще говоря, VPC-CNI имеет лучшую производительность сети, но ограничен количеством ядер машины. Если приложения в основном представляют собой небольшие микросервисы (использование памяти в пределах 1G), то использование GlobalRouter было бы более подходящим.
Кроме того, CIDR контейнерной сети также является болевой точкой. Если диапазон CIDR установлен слишком маленьким, будет слишком мало распределяемых IP-адресов pod/service, что также повлияет на финальный масштаб приложения.
План аварийного восстановления
Однажды передо мной была прекрасная namespace, которую я не ценил, пока случайно не удалил её и не понял, что всё слишком поздно. Если небеса могли бы дать мне ещё один шанс, я действительно хотел бы, чтобы мой мозг не был залит водой в то время.
Я всё ещё помню тот инцидент. Чтобы восстановить общую доступность бизнеса, половине технического отдела пришлось работать сверхурочно до очень позднего времени. Но в процессе восстановления мы фактически обнаружили некоторые области, где предыдущая работа была недостаточной: например, предоставление разработчикам разрешения на изменение ресурсов в определённом namespace, но разработчики обновляли приложения для удобства, напрямую изменяя ENV в YAML, а затем забывали конфигурацию позже; например, не резервируя kubernetes YAML и т.д.
Объединяя весь процесс доставки приложений, я позже создал относительно простое решение:
- Периодическое резервное копирование дисков сервера кода
- Синхронизация kubernetes YAML в git-репозиторий с помощью kube-backup
- Учётные записи для извлечения образов имеют только разрешения
pull image - Размещение ресурсов производственного уровня в пространстве имён по умолчанию (потому что это пространство имён по умолчанию
namespaceнельзя удалить) - Отключение разрешений на изменение для разработчиков, все конфигурации проходят через центр конфигурации, и удаление большинства configmaps
- Отключение моего собственного административного аккаунта, выделение сертификата
api-serverбез разрешений на удаление
Пункт 5 спорен. Лично я думаю, что когда мы зависим от определённой технологии, мы должны учитывать “антизависимость”. Антизависимость означает: если эта технология устареет или возникнут серьёзные проблемы, каков наш план B?
Хотя kubernetes предоставляет механизм горячего обновления, чтобы уменьшить нагрузку на ETCD и уменьшить зависимость от kubernetes, мы поместили конфигурации в consul.
Лучший врач лечит до болезни, худший врач лечит после болезни. Я надеюсь, что все не ждут, как я, пока проблемы не появятся, прежде чем думать о том, как их решить.
Управление узлами
Планирование ресурсов узлов TKE — это на самом деле несколько сложная проблема “оценки Ферми”. Правильное управление и планирование узлов помогает лучше снизить затраты и повысить эффективность.
Конфигурация узла должна соответствовать фактическим ситуациям. Для вычислительно-интенсивных приложений выделяйте больше CPU, в то время как для приложений, потребляющих память, я лично предпочитаю узлы 4-core 32G больше.
Сервисы со специальными требованиями к узлам могут использовать Node Affinity для развёртывания, чтобы планировать на узлы, которые соответствуют требованиям. Например, планировать MySQL на модели с высоким IO для повышения эффективности чтения/записи данных.
Узлы типа GPU обычно имеют специальные цели, и неподходяще доставлять их вместе с обычными узлами пользователям. Поэтому я обычно рекомендую использовать taints узлов для изоляции их от других узлов, обеспечивая, чтобы узлы специального типа не запускали контейнеры, которые не соответствуют ожиданиям.
1
kubectl taint node $no just-for-gpu-application=true:NoExecute
1
2
3
4
5
6
7
tolerations:
- key: "just-for-gpu-application"
operator: "Exists"
effect: "NoSchedule"
- key: "just-for-gpu-application"
operator: "Exists"
effect: "NoExecute"
Я лично не рекомендую добавлять узлы с малой конфигурацией (например, 1-core 2G) в кластеры kubernetes, потому что это теряет “эластичность” масштабирования приложений. Например, приложение изначально получает 0.7 ядра 1.5G, но после работы в течение некоторого времени обнаруживается, что требуется конфигурация 2 ядра 4G. Переназначение может только отказаться от исходного узла. Более того, такие узлы с низкой конфигурацией не очень соответствуют философии проектирования распределённых систем—достижению высокой доступности через избыточность ресурсов.
Итак, всегда ли лучше более высокая конфигурация узла?
На этот вопрос на самом деле нет стандартного ответа. Но я много раз сталкивался с общими сбоями узлов, вызванными docker hang узла или Not Ready, или даже чрезмерной нагрузкой узла. Это вызывает лавины и недоступность всех приложений на узле.
Для проблем, вызванных сбоями узлов с одной точкой отказа, в дополнение к установке соответствующих политик оповещений в облачном мониторинге, мы улучшили NPD на основе версии сообщества. Он поддерживает самовосстановление узлов (см. “Использование плагина TKE NPDPlus для повышения способности узлов к самовосстановлению при сбоях”). Пользователи могут выбрать перезапуск среды выполнения контейнеров или даже перезапуск CVM.
Кроме того, наш TKE также поддерживает использование групп размещения для достижения аварийного восстановления на физическом уровне, используя антиаффинность на уровне базового оборудования облачного сервера для рассеивания Pods по разным узлам.
Управление бизнесом
Система DevOps kubernetes является вызовом как для операций, так и для разработки. Разработка должна адаптироваться к архитектуре pod эфемерного существования, принимая изменения, принесённые контейнеризацией приложений.
Волатильность
Всё пройдёт.
В моём мире это может быть единственное предложение, которое можно считать истиной. 《人間失格》
Волатильность имеет несколько значений. Во-первых, разработка должна адаптироваться к тому факту, что IP-адреса контейнеров изменчивы. Во-вторых, файловая система также изменчива. Ранее, когда код развёртывался на CVM, мы могли устанавливать различные инструменты отладки на сервере, но в контейнерной среде мы сталкиваемся с дилеммой: должны ли мы упаковывать инструменты отладки в образ или использовать kubectl exec для входа в контейнер и установки их?
Если мы упаковываем инструменты в контейнеры, образ будет включать некоторый контент, не связанный с бизнесом, делая образ больше и развёртывание медленнее. Если мы устанавливаем инструменты отладки в контейнеры, мы сталкиваемся с большим количеством повторяющейся работы каждый раз, когда обновляем/перезапускаем.
Я также не дам стандартного ответа здесь, но расскажу вам, как управление бизнесом может быть выполнено в других измерениях.
Наблюдаемость
В настоящее время взгляд отрасли на наблюдаемость заключается в том, чтобы разделить её на:
- Metrics
- Tracing
- Logging
Эти части. В этом отношении мы в Tencent Cloud построили решение облачного мониторинга на основе Prometheus, а также сбор логов и хранение событий. Эти решения охватывают мониторинг метрик, сбор логов, хранение событий, мониторинг оповещений и другие аспекты.
С точки зрения Tracing, отслеживание и мониторинг распределённых сервисов могут быть дополнительно подразделены на неинвазивные и инвазивные решения. Инвазивные решения относятся к изменению кода, например, добавлению определённых заголовков запросов в цепочку запросов; неинвазивные решения — это теперь популярный подход Service Mesh, позволяющий бизнесу больше сосредоточиться на бизнесе, в то время как управление трафиком обрабатывается sidecar. Из-за ограничений пространства я не буду здесь расширять это.
Изоляция
Изоляция ресурсов
Изоляция ресурсов может быть дополнительно подразделена на изоляцию ресурсов в пределах одного кластера и мультитенантную изоляцию. В предыдущих главах я упоминал использование taints узлов для изоляции обычных узлов и узлов GPU, что на самом деле является формой изоляции ресурсов.
Для мультитенантности самая простая реализация — один пользователь на namespace, затем использование LimitRange для ограничения.
Изоляция ресурсов существует не только внутри кластеров, но и вне кластеров. Иногда мы строим кластеры в одном VPC или между VPC для достижения полной изоляции ресурсов, но этот подход также создаёт новые проблемы с межоблачной связью (на уровне VPC мы поддерживаем связь через пиринговые соединения и облачную сеть). Это будет новым вызовом для всей архитектуры микросервисов.
Сетевая изоляция
Чтобы понять сетевую изоляцию, мы должны сначала понять сетевую связность в обратном порядке. В качестве примера возьмём режим VXLAN Flannel, узлы кластера kubernetes, использующие этот режим, взаимосвязаны. И на самом деле, services между namespaces также взаимосвязаны.
Некоторые могут задать вопрос здесь: разве kubernetes не основан на namespace для изоляции ресурсов? Почему доступ между namespaces взаимосвязан?
Здесь мы должны упомянуть файл /etc/resolv.conf, который kubernetes внедряет. В качестве примера возьмём любой pod с неизменённой сетевой конфигурацией под default:
1
2
3
4
cat /etc/resolv.conf
nameserver <kube-dns-vip>
search default.svc.cluster.local svc.cluster.local cluster.local localdomain
options ndots:5
Эта конфигурация означает, что домены с менее чем пятью уровнями проходят через coreDNS, приоритизированные в соответствии с порядком search. Например, разрешение baidu.com происходит так:
1
2
3
4
5
6
7
sh-4.2# host -v baidu.com
Trying "baidu.com.<namespace>.svc.cluster.local"
Trying "baidu.com.svc.cluster.local"
Trying "baidu.com.cluster.local"
Trying "baidu.com.localdomain"
Trying "baidu.com"
......
Здесь мы можем увидеть ключ. Например, если мы создадим сервис с именем tke-six-six-six под default и kube-system, причина, по которой доступ к six под default не переходит к сервису, определённому в kube-system, заключается в том, что он сначала пытается разрешить tke-six-six-six.default.svc.cluster.local. Но если мы напрямую обращаемся к tke-six-six-six.kube-system.svc.cluster.local, это также возможно. Так называемая изоляция — это просто манипуляция на уровне разрешения домена.
Сетевая изоляция особенно важна в мультитенантных средах. Мы не можем гарантировать, что весь входящий и исходящий трафик является законным, поэтому мы сначала предполагаем, что весь трафик незаконен, позволяя только трафику, который соответствует требованиям, получать доступ к приложениям. Если не использовать istio, официальная версия также предоставляет Network Policy на основе ip, namespaceSelector и podSelector.
Самовосстановление
Здесь я снова применю первый принцип распределённых систем—достижение доступности системы через избыточность ресурсов. Как правило, чтобы избежать недоступности одного узла, мы рекомендуем пользователям установить приложения на 2 или более реплик и установить podAntiAffinity.
1
2
3
4
5
6
7
8
9
10
11
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- my-pipi-server
topologyKey: kubernetes.io/hostname
weight: 100
Кроме того, мы обычно рекомендуем пользователям добавить следующие конфигурации:
- readinessProbe (проверка готовности)
- livenessProbe (проверка здоровья)
- preStop hook
Важность проверок готовности и проверок здоровья не требует объяснений. preStop hook может установить короткое время сна, потому что действие kube-proxy по обновлению правил пересылки узлов не является немедленным. Добавление preStop hook к контейнерам в Pods заставляет Pods спать и ждать в течение периода перед истинным уничтожением, давая время для Endpoint controller и kube-proxy для обновления Endpoints и правил пересылки.
Обратите внимание, что настройка по умолчанию terminationGracePeriodSeconds составляет 30 секунд. Если время preStop hook превышает 30 секунд, значение terminationGracePeriodSeconds также должно быть изменено соответственно.
Резюме
То, что изучено из книг, поверхностно; истинное знание приходит из практики. Контейнеризация приносит новые испытания как для операций, так и для разработки, поэтому не относитесь к этому легкомысленно.
Я надеюсь, что все, будь то в операциях или разработке, смогут извлечь управленческие навыки из операций и разблокировать новые переворот программистские ходы в разработке.
Отсутствие проблем — самая большая проблема. Если нет ответа, найдите ответ сами!
Ссылки
[1] Introducing Container Runtime Interface (CRI) in Kubernetes https://kubernetes.io/blog/2016/12/container-runtime-interface-cri-in-kubernetes/
[2] K8s宣布弃用Docker,千万别慌! https://cloud.tencent.com/document/product/457/11741
[3] 解读:云原生下的可观察性发展方向 https://cloudnative.to/blog/cloud-native-observability/
[4] 十分钟漫谈容器网络方案 01—Flannel https://www.infoq.cn/article/rnbqhui1wipzj6bjiwet