首先,我们先理清一个概念:
关系型数据库是非关系数据库的真子集,非关系数据库是时间序列数据库的真子集。
关系型数据库

关系型数据库是这样定义的:
采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,以便于用户理解,关系型数据库这一系列的行和列被称为表,一组表组成了数据库。
关系型数据库的集大成者是 MySQL 。关系型数据库的问题在于强调“关系”。但实际上,对象之间的关系是弱关系。强关系只是一种特例。
举个例子。我们定义三个对象:小明,小红和小王。小明和小红是同居的情侣,小王住在他们隔壁。有一天,小明回到家看到小红和小王呆在同一个房间里。这时小明会有什么想法呢?
他到底应该说小王和小红在过家家呢,还是认同他们的解释,认为小王是在给房间里换电灯泡呢?
这个关系的问题,其实就是关系型数据库的最大问题——乱搞关系。在现在很多开发设计规范里面,已经把关系型数据库当做一个数据存储的仓库(堆表),禁止存储过程,也禁止了外键。可以说,这是历史发展的必然结果。
非关系型数据库
那么,非关系型数据库,自然就是 NoSQL 。
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
其中有以 Redis 为代表的 key-value 数据库,也有以 MongoDB 为代表的文档型数据库。

Redis 是基于内存的(虽然也可以持久化到硬盘),内存是相当珍贵的资源。资源的有限限制了资源的广泛使用。

MongoDB 其实有点像 Excel ,在 Excel 文件里面,每一行可以有任意个单元格。
比如,新亘结衣在 MongoDB 中的“爱好”和“配偶”不是空(Null),而是压根就没有这个字段。
| 姓名 | 性别 | 电话 | 爱好 | 偶像 | 特长 |
|---|---|---|---|---|---|
| 王蟑螂 | 男 | +8617051026064 | 吃耙耙 | 新亘结衣 | |
| 新亘结衣 | 女 | +8113766621544 | 唱歌 |
如果说 Redis 的问题在于内存过于珍贵,那么我觉得非关系型数据库的问题在于描述的对象“不够自然”。
时间序列数据库

“不够自然”的意思,就是缺少“时间”这个属性。实际上,时间才是数据的第一属性。任何数据如果没有时间这个属性,那么都变得毫无意义。所以很多表在设计的时候,从规范层面就是这样说的:要有创建时间这个属性。
除此以外,时间序列数据库应该满足这样一个特征:不可变性(Immutable) 。不可变性是指数据录入之后不可变更。数据库的业务靠实时数据流引擎去处理。
时间序列数据库,才是最切合现实世界的模型。举个最简单的例子:我要用小拳拳捶你胸口。我们先简化一下这个动作,然后再录入到时序数据库里面吧 ~
“小拳拳捶你胸口”,最简化的模型就是,描述一个点在三维空间里面“线段”(因为移动的距离有限,所以叫线段)运动到另外一个点。
在三维空间里面,求两点之间的距离,其实跟在一维空间求两点的距离,没啥差别,泛化勾股定理就行了。我会这样说,勾股定理,是升高维度的“梯子”。
有这样的认识,在时序数据库里面,定义数据非常之自然而简单。还是以这个问题为例,解决这个问题,只需要隔一段采集数据,并录入即可。
| 时间 | X | Y | Z |
|---|---|---|---|
| 2020-04-01 09:35:00 | 1 | 1 | 1 |
| 2020-04-01 09:35:01 | 2 | 2 | 2 |
| 2020-04-01 09:35:02 | 3 | 3 | 3 |
| 2020-04-01 09:35:03 | 3 | 3 | 3 |
监控分析
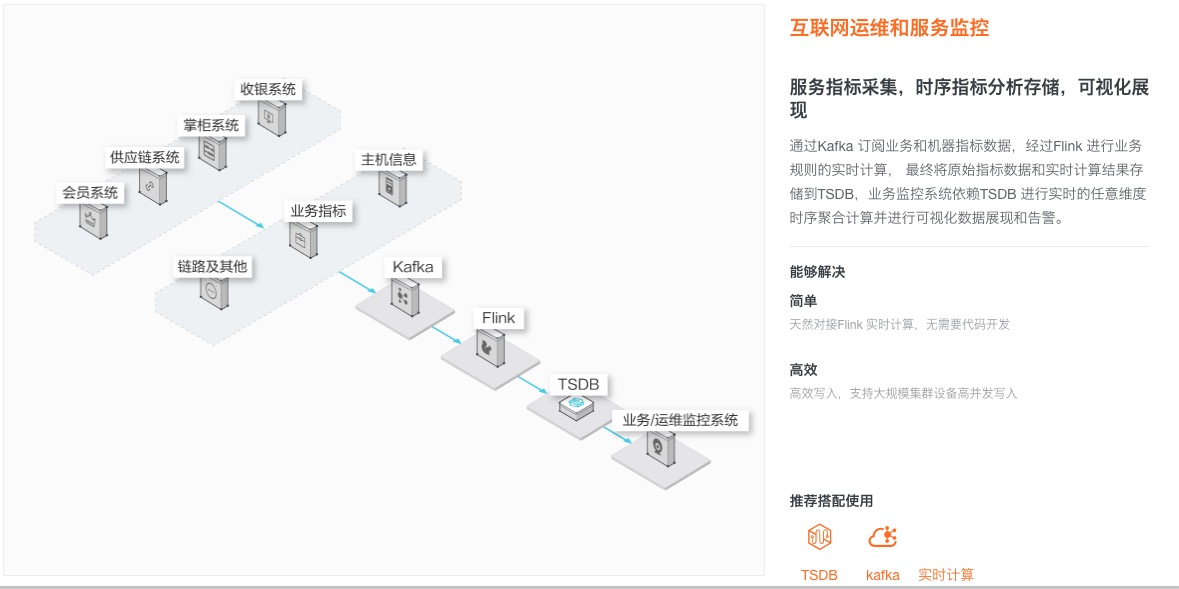
杭州迪火科技监控平台负责人董兵林是这样说的:“(阿里云)TSDB 帮助我们解决了指标数据存储的问题,其表现出的极佳性能,零运维成本,数据永久存储,专门的技术支持,都是我们一直使用的原因。目前我们可以很方便的查看实时指标信息和回溯历史的指标信息,及时发现问题,为进一步的决策提供依据,TSDB 是我们不可缺少的一部分。”
趋势分析
趋势分析,是用来预测未来的一种概率。比如,在上面的数据中,用三维直角坐标系建模,就会得到一条线性趋势线。我们可以预测2020-04-01 09:35:04,我的小拳拳大概率会落于(4,4,4)这个坐标点。
溯源分析
溯源分析跟趋势分析是相反的,是时间倒序的另外一种数据结构。
| 时间 | X | Y | Z |
|---|---|---|---|
| 2020-04-01 09:35:03 | 3 | 3 | 3 |
| 2020-04-01 09:35:02 | 3 | 3 | 3 |
| 2020-04-01 09:35:01 | 2 | 2 | 2 |
| 2020-04-01 09:35:00 | 1 | 1 | 1 |
在这个问题中,我们建立一条线性趋势线之后,可以用溯源推理分析出2020-04-01 09:34:59我的拳头大概率位于 (0,0,0) 。
也就是说,这是用来预测“过去”的一种概率。溯源分析可以用于刑侦破案,历史遗留问题溯因等场景。
现在的时间序列化数据库,每一行的记录还是比较结构化的。而且,被大量应用于监控领域,这其实是一种误解。 广义的时间序列数据库,每一行数据支持任意属性。
结论
我相信在未来,时序数据库将超越关系型数据库和非关系型数据库,成为应用开发的首选方案。
参考链接
First, let’s clarify a concept:
Relational databases are a proper subset of non-relational databases, and non-relational databases are a proper subset of time-series databases.
Relational Databases
Relational databases are defined as:
Databases that use a relational model to organize data, storing data in rows and columns for user understanding. This series of rows and columns in relational databases is called tables, and a group of tables forms a database.
The pinnacle of relational databases is MySQL. The problem with relational databases lies in emphasizing “relationships.” But actually, relationships between objects are weak relationships. Strong relationships are just a special case.
For example. Let’s define three objects: Xiao Ming, Xiao Hong, and Xiao Wang. Xiao Ming and Xiao Hong are cohabiting lovers, and Xiao Wang lives next door. One day, Xiao Ming comes home and sees Xiao Hong and Xiao Wang in the same room. What would Xiao Ming think?
Should he say Xiao Wang and Xiao Hong are playing house, or accept their explanation that Xiao Wang is changing a light bulb in the room?
This relationship problem is actually the biggest problem with relational databases—messing with relationships. In many current development design standards, relational databases have been treated as a data storage warehouse (heap tables), prohibiting stored procedures and foreign keys. It can be said this is an inevitable result of historical development.
Non-Relational Databases
So, non-relational databases are naturally NoSQL.
NoSQL, generally referring to non-relational databases. With the rise of internet web2.0 websites, traditional relational databases have shown inadequacy in handling web2.0 websites, especially ultra-large-scale and high-concurrency SNS-type web2.0 purely dynamic websites, with many insurmountable problems. Non-relational databases have developed very rapidly due to their own characteristics. NoSQL databases emerged to solve the challenges brought by large-scale data collections with multiple data types, especially big data application problems.
Among them are key-value databases represented by Redis, and document databases represented by MongoDB.
Redis is memory-based (though it can also persist to disk), and memory is a quite precious resource. The limitation of resources restricts the widespread use of resources.
MongoDB is actually a bit like Excel. In Excel files, each row can have any number of cells.
For example, Yui Aragaki’s “hobbies” and “spouse” in MongoDB are not null, but simply don’t have these fields at all.
| 姓名 | 性别 | 电话 | 爱好 | 偶像 | 特长 |
|---|---|---|---|---|---|
| 王蟑螂 | 男 | +8617051026064 | 吃耙耙 | 新亘结衣 | |
| 新亘结衣 | 女 | +8113766621544 | 唱歌 |
If Redis’s problem is that memory is too precious, then I think the problem with non-relational databases is that the objects they describe are “not natural enough.”
Time-Series Databases
“Not natural enough” means lacking the “time” attribute. Actually, time is the first attribute of data. Any data without the time attribute becomes meaningless. So many tables in design specifications say this at the specification level: must have a creation time attribute.
Besides, time-series databases should satisfy this characteristic: Immutability. Immutability means data cannot be changed after entry. Database business is handled by real-time data stream engines.
Time-series databases are the model that best fits the real world. Take the simplest example: I want to hit your chest with little fists. Let’s simplify this action first, then enter it into a time-series database~
“Little fists hitting your chest,” the most simplified model is describing a point moving from one point to another in three-dimensional space as a “line segment” (because the movement distance is limited, it’s called a line segment).
In three-dimensional space, finding the distance between two points is actually no different from finding the distance between two points in one-dimensional space—just generalize the Pythagorean theorem. I would say the Pythagorean theorem is the “ladder” for raising dimensions.
With this understanding, defining data in time-series databases is very natural and simple. Still using this problem as an example, solving this problem only requires collecting data at intervals and entering it.
| 时间 | X | Y | Z |
|---|---|---|---|
| 2020-04-01 09:35:00 | 1 | 1 | 1 |
| 2020-04-01 09:35:01 | 2 | 2 | 2 |
| 2020-04-01 09:35:02 | 3 | 3 | 3 |
| 2020-04-01 09:35:03 | 3 | 3 | 3 |
Monitoring Analysis
Dong Binglin, head of Hangzhou Dihuo Technology’s monitoring platform, said this: “(Alibaba Cloud) TSDB helped us solve the problem of metric data storage. Its excellent performance, zero operational costs, permanent data storage, and dedicated technical support are all reasons we continue to use it. Currently, we can easily view real-time metric information and trace back historical metric information, discover problems in time, and provide basis for further decisions. TSDB is an indispensable part for us.”
Trend Analysis
Trend analysis is used to predict the future probabilistically. For example, in the data above, modeling with a three-dimensional Cartesian coordinate system yields a linear trend line. We can predict that at 2020-04-01 09:35:04, my little fists will most likely land at coordinate point (4, 4, 4).
Traceability Analysis
Traceability analysis is the opposite of trend analysis—it’s another data structure in reverse chronological order.
| 时间 | X | Y | Z |
|---|---|---|---|
| 2020-04-01 09:35:03 | 3 | 3 | 3 |
| 2020-04-01 09:35:02 | 3 | 3 | 3 |
| 2020-04-01 09:35:01 | 2 | 2 | 2 |
| 2020-04-01 09:35:00 | 1 | 1 | 1 |
In this problem, after establishing a linear trend line, we can use traceability reasoning to analyze that at 2020-04-01 09:34:59, my fist was most likely at (0,0,0).
That is to say, this is used to predict the “past” probabilistically. Traceability analysis can be used in scenarios like criminal investigation, tracing causes of historical issues, etc.
Current time-series databases still have relatively structured records per row. And they’re widely applied in the monitoring field, which is actually a misunderstanding. Generalized time-series databases support arbitrary attributes per row of data.
Conclusion
I believe that in the future, time-series databases will surpass relational and non-relational databases to become the preferred solution for application development.
References
まず、概念を明確にしましょう:
リレーショナルデータベースは非リレーショナルデータベースの真部分集合であり、非リレーショナルデータベースは時系列データベースの真部分集合です。
リレーショナルデータベース
リレーショナルデータベースは次のように定義されます:
リレーショナルモデルを使用してデータを整理するデータベースで、ユーザーの理解のために行と列の形式でデータを保存します。リレーショナルデータベースのこの一連の行と列はテーブルと呼ばれ、テーブルのグループがデータベースを形成します。
リレーショナルデータベースの集大成はMySQLです。リレーショナルデータベースの問題は「関係」を強調することにあります。しかし、実際には、オブジェクト間の関係は弱い関係です。強い関係は単なる特殊なケースです。
例を挙げましょう。3つのオブジェクトを定義します:小明、小红、小王。小明と小红は同棲している恋人で、小王は隣に住んでいます。ある日、小明が家に帰ると、小红と小王が同じ部屋にいるのを見ます。この時、小明は何を考えるでしょうか?
小王と小红がままごとをしていると言うべきか、それとも彼らの説明を受け入れ、小王が部屋で電球を交換していると考えるべきでしょうか?
この関係の問題は、実際にはリレーショナルデータベースの最大の問題—関係をめちゃくちゃにすることです。現在の多くの開発設計規格では、リレーショナルデータベースをデータストレージの倉庫(ヒープテーブル)として扱い、ストアドプロシージャと外部キーを禁止しています。これは歴史的発展の必然的な結果と言えます。
非リレーショナルデータベース
では、非リレーショナルデータベースは当然NoSQLです。
NoSQL、一般的に非リレーショナルデータベースを指します。インターネットweb2.0ウェブサイトの台頭により、従来のリレーショナルデータベースは、web2.0ウェブサイト、特に超大規模で高同時実行のSNSタイプのweb2.0純動的ウェブサイトを処理する際に不十分であることが示され、克服困難な問題が多く発生しています。非リレーショナルデータベースは、その特性により非常に急速に発展しています。NoSQLデータベースは、大規模データコレクションの複数のデータタイプ、特にビッグデータアプリケーションの問題によってもたらされる課題を解決するために出現しました。
その中には、Redisを代表とするキー値データベースと、MongoDBを代表とするドキュメントデータベースがあります。
Redisはメモリベースです(ディスクに永続化することもできますが)、メモリは非常に貴重なリソースです。リソースの制限がリソースの広範な使用を制限しています。
MongoDBは実際にはExcelに少し似ています。Excelファイルでは、各行に任意の数のセルを含めることができます。
例えば、新垣結衣のMongoDBでの「趣味」と「配偶者」はnullではなく、単にこれらのフィールドがまったく存在しません。
| 姓名 | 性别 | 电话 | 爱好 | 偶像 | 特长 |
|---|---|---|---|---|---|
| 王蟑螂 | 男 | +8617051026064 | 吃耙耙 | 新亘结衣 | |
| 新亘结衣 | 女 | +8113766621544 | 唱歌 |
Redisの問題がメモリが非常に貴重であることであるなら、非リレーショナルデータベースの問題は、記述するオブジェクトが「十分に自然ではない」ことだと思います。
時系列データベース
「十分に自然ではない」とは、「時間」という属性が欠けていることを意味します。実際、時間はデータの第一属性です。時間属性のないデータはすべて無意味になります。だから多くのテーブルは設計規格で、規格レベルでこう言っています:作成時間属性が必要です。
それ以外に、時系列データベースは次の特性を満たす必要があります:不変性(Immutability)。不変性とは、データが入力後に変更できないことを意味します。データベースのビジネスはリアルタイムデータストリームエンジンによって処理されます。
時系列データベースは、現実世界に最も適合するモデルです。最も簡単な例を挙げましょう:小さな拳で胸を叩きたい。まずこのアクションを簡略化してから、時系列データベースに入力しましょう〜
「小さな拳で胸を叩く」、最も簡略化されたモデルは、3次元空間内の1つの点が別の点に移動する「線分」(移動距離が限られているため、線分と呼ばれます)を記述することです。
3次元空間では、2点間の距離を求めることは、実際には1次元空間で2点間の距離を求めることと違いはなく、ピタゴラスの定理を一般化するだけです。ピタゴラスの定理は、次元を上げる「はしご」だと言えます。
この理解により、時系列データベースでデータを定義することは非常に自然で簡単です。この問題を例として、この問題を解決するには、一定間隔でデータを収集して入力するだけです。
| 时间 | X | Y | Z |
|---|---|---|---|
| 2020-04-01 09:35:00 | 1 | 1 | 1 |
| 2020-04-01 09:35:01 | 2 | 2 | 2 |
| 2020-04-01 09:35:02 | 3 | 3 | 3 |
| 2020-04-01 09:35:03 | 3 | 3 | 3 |
監視分析
杭州迪火科技監視プラットフォーム責任者の董兵林はこう言いました:「(Alibaba Cloud)TSDBは指標データストレージの問題を解決してくれました。その優れたパフォーマンス、ゼロ運用コスト、永続的なデータストレージ、専用の技術サポートは、私たちが使い続ける理由です。現在、リアルタイムの指標情報を簡単に表示し、履歴の指標情報を追跡し、問題をタイムリーに発見し、さらなる決定の根拠を提供できます。TSDBは私たちにとって不可欠な部分です。」
傾向分析
傾向分析は、未来を確率的に予測するために使用されます。例えば、上記のデータで、3次元デカルト座標系でモデリングすると、線形トレンドラインが得られます。2020-04-01 09:35:04に、私の小さな拳が座標点(4、4、4)に落ちる可能性が高いと予測できます。
トレーサビリティ分析
トレーサビリティ分析は傾向分析の逆—逆時系列順の別のデータ構造です。
| 时间 | X | Y | Z |
|---|---|---|---|
| 2020-04-01 09:35:03 | 3 | 3 | 3 |
| 2020-04-01 09:35:02 | 3 | 3 | 3 |
| 2020-04-01 09:35:01 | 2 | 2 | 2 |
| 2020-04-01 09:35:00 | 1 | 1 | 1 |
この問題では、線形トレンドラインを確立した後、トレーサビリティ推論を使用して、2020-04-01 09:34:59に私の拳が(0,0,0)にあった可能性が高いと分析できます。
つまり、これは「過去」を確率的に予測するために使用されます。トレーサビリティ分析は、刑事調査、歴史的問題の原因追跡などのシナリオで使用できます。
現在の時系列データベースは、各行のレコードが比較的構造化されています。そして、監視分野で広く適用されていますが、これは実際には誤解です。 一般化された時系列データベースは、各行のデータで任意の属性をサポートします。
結論
私は、将来、時系列データベースがリレーショナルデータベースと非リレーショナルデータベースを超えて、アプリケーション開発の優先ソリューションになると信じています。
参考リンク
Сначала давайте уточним концепцию:
Реляционные базы данных являются собственным подмножеством нереляционных баз данных, а нереляционные базы данных являются собственным подмножеством баз данных временных рядов.
Реляционные базы данных
Реляционные базы данных определяются как:
Базы данных, использующие реляционную модель для организации данных, хранящие данные в строках и столбцах для понимания пользователем. Эта серия строк и столбцов в реляционных базах данных называется таблицами, а группа таблиц образует базу данных.
Вершиной реляционных баз данных является MySQL. Проблема реляционных баз данных заключается в акценте на “отношениях”. Но на самом деле, отношения между объектами являются слабыми отношениями. Сильные отношения — это всего лишь особый случай.
Например. Давайте определим три объекта: Сяо Мин, Сяо Хун и Сяо Ван. Сяо Мин и Сяо Хун — сожительствующие любовники, а Сяо Ван живёт по соседству. Однажды Сяо Мин приходит домой и видит Сяо Хун и Сяо Вана в одной комнате. Что подумает Сяо Мин?
Должен ли он сказать, что Сяо Ван и Сяо Хун играют в дом, или принять их объяснение, что Сяо Ван меняет лампочку в комнате?
Эта проблема отношений — это на самом деле самая большая проблема реляционных баз данных—путаница с отношениями. Во многих текущих стандартах проектирования разработки реляционные базы данных были обработаны как склад хранения данных (кучи таблиц), запрещая хранимые процедуры и внешние ключи. Можно сказать, что это неизбежный результат исторического развития.
Нереляционные базы данных
Итак, нереляционные базы данных, естественно, это NoSQL.
NoSQL, в общем, относящийся к нереляционным базам данных. С подъёмом интернет-сайтов web2.0 традиционные реляционные базы данных показали неадекватность в обработке сайтов web2.0, особенно ультра-крупномасштабных и высококонкурентных SNS-типа чисто динамических сайтов web2.0, с множеством непреодолимых проблем. Нереляционные базы данных развивались очень быстро благодаря своим характеристикам. Базы данных NoSQL появились для решения проблем, вызванных крупномасштабными коллекциями данных с множественными типами данных, особенно проблемами приложений больших данных.
Среди них есть базы данных ключ-значение, представленные Redis, и документные базы данных, представленные MongoDB.
Redis основан на памяти (хотя может также сохраняться на диск), а память — довольно ценный ресурс. Ограничение ресурсов ограничивает широкое использование ресурсов.
MongoDB на самом деле немного похож на Excel. В файлах Excel каждая строка может иметь любое количество ячеек.
Например, “хобби” и “супруг” Юи Арагаки в MongoDB не null, а просто вообще не имеют этих полей.
| 姓名 | 性别 | 电话 | 爱好 | 偶像 | 特长 |
|---|---|---|---|---|---|
| 王蟑螂 | 男 | +8617051026064 | 吃耙耙 | 新亘结衣 | |
| 新亘结衣 | 女 | +8113766621544 | 唱歌 |
Если проблема Redis в том, что память слишком ценна, то я думаю, что проблема нереляционных баз данных в том, что объекты, которые они описывают, “недостаточно естественны”.
Базы данных временных рядов
“Недостаточно естественно” означает отсутствие атрибута “время”. На самом деле, время — это первый атрибут данных. Любые данные без атрибута времени становятся бессмысленными. Поэтому многие таблицы в спецификациях проектирования говорят об этом на уровне спецификации: должен быть атрибут времени создания.
Кроме того, базы данных временных рядов должны удовлетворять этой характеристике: Неизменяемость. Неизменяемость означает, что данные не могут быть изменены после ввода. Бизнес базы данных обрабатывается движками потоков данных в реальном времени.
Базы данных временных рядов — это модель, которая лучше всего подходит реальному миру. Возьмём простейший пример: я хочу ударить вас по груди маленькими кулачками. Давайте сначала упростим это действие, а затем введём его в базу данных временных рядов~
“Маленькие кулачки бьют по груди,” самая упрощённая модель — это описание точки, движущейся от одной точки к другой в трёхмерном пространстве как “линейный сегмент” (потому что расстояние движения ограничено, это называется линейным сегментом).
В трёхмерном пространстве нахождение расстояния между двумя точками на самом деле ничем не отличается от нахождения расстояния между двумя точками в одномерном пространстве—просто обобщите теорему Пифагора. Я бы сказал, что теорема Пифагора — это “лестница” для повышения размерности.
С этим пониманием определение данных в базах данных временных рядов очень естественно и просто. Всё ещё используя эту проблему в качестве примера, решение этой проблемы требует только сбора данных с интервалами и ввода их.
| 时间 | X | Y | Z |
|---|---|---|---|
| 2020-04-01 09:35:00 | 1 | 1 | 1 |
| 2020-04-01 09:35:01 | 2 | 2 | 2 |
| 2020-04-01 09:35:02 | 3 | 3 | 3 |
| 2020-04-01 09:35:03 | 3 | 3 | 3 |
Анализ мониторинга
Дун Бинлинь, руководитель платформы мониторинга Hangzhou Dihuo Technology, сказал это: “(Alibaba Cloud) TSDB помог нам решить проблему хранения данных метрик. Его отличная производительность, нулевые операционные затраты, постоянное хранение данных и выделенная техническая поддержка — все причины, по которым мы продолжаем использовать его. В настоящее время мы можем легко просматривать информацию о метриках в реальном времени и отслеживать историческую информацию о метриках, своевременно обнаруживать проблемы и предоставлять основу для дальнейших решений. TSDB — незаменимая часть для нас.”
Анализ трендов
Анализ трендов используется для вероятностного прогнозирования будущего. Например, в данных выше, моделирование с трёхмерной декартовой системой координат даёт линейную линию тренда. Мы можем предсказать, что в 2020-04-01 09:35:04 мои маленькие кулачки, скорее всего, приземлятся в координатной точке (4, 4, 4).
Анализ прослеживаемости
Анализ прослеживаемости противоположен анализу трендов—это другая структура данных в обратном хронологическом порядке.
| 时间 | X | Y | Z |
|---|---|---|---|
| 2020-04-01 09:35:03 | 3 | 3 | 3 |
| 2020-04-01 09:35:02 | 3 | 3 | 3 |
| 2020-04-01 09:35:01 | 2 | 2 | 2 |
| 2020-04-01 09:35:00 | 1 | 1 | 1 |
В этой проблеме, после установления линейной линии тренда, мы можем использовать рассуждения о прослеживаемости, чтобы проанализировать, что в 2020-04-01 09:34:59 мой кулак, скорее всего, был в (0,0,0).
То есть, это используется для вероятностного прогнозирования “прошлого”. Анализ прослеживаемости может использоваться в сценариях, таких как уголовное расследование, отслеживание причин исторических проблем и т.д.
Текущие базы данных временных рядов всё ещё имеют относительно структурированные записи в каждой строке. И они широко применяются в области мониторинга, что на самом деле является недоразумением. Обобщённые базы данных временных рядов поддерживают произвольные атрибуты в каждой строке данных.
Заключение
Я верю, что в будущем базы данных временных рядов превзойдут реляционные и нереляционные базы данных, чтобы стать предпочтительным решением для разработки приложений.
Ссылки
💬 讨论 / Discussion
对这篇文章有想法?欢迎在 GitHub 上发起讨论。
Have thoughts on this post? Start a discussion on GitHub.