问题
2020-03-05 星期四,下午一点.百度流量异常地高,超过了200Mbps.

联系了网宿那边的技术,说是百度的爬虫在捣鬼.
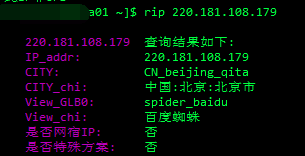
让他们导出了一系列IP
切换到阿里云之后,发现百度竟然还把我网宿的IP给记住了,真是666.
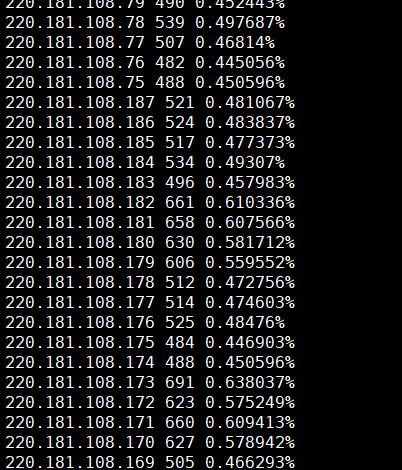
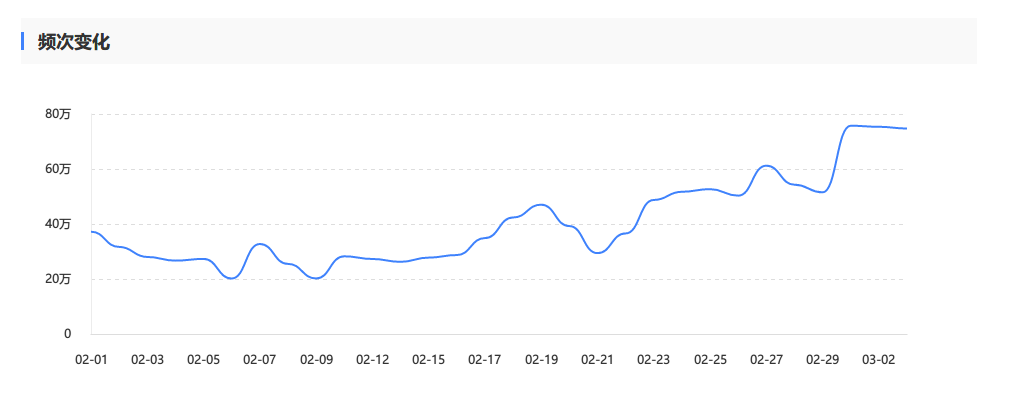
然后我查看了站长后台,抓取的频次确实高了些.
结论
- 123.125 xxx xxx
- 220.181 xxx xxx
这2个网段都是百度那边的IP,原则上要放行.而且他们喜欢在周四更新.
Problem
Thursday, March 5, 2020, 1:00 PM. Baidu traffic was abnormally high, exceeding 200Mbps.
Contacted the technical staff at Wangsu, who said Baidu’s crawlers were causing trouble.
Had them export a series of IPs.
After switching to Alibaba Cloud, I found that Baidu had actually remembered my Wangsu IP, really impressive.
Then I checked the webmaster backend, and the crawl frequency was indeed a bit high.
Conclusion
- 123.125 xxx xxx
- 220.181 xxx xxx
These two IP ranges are both from Baidu’s side. In principle, they should be allowed. And they like to update on Thursdays.
問題
2020年3月5日(木曜日)午後1時。百度のトラフィックが異常に高く、200Mbpsを超えました。
網宿の技術担当者に連絡したところ、百度のクローラーが原因だと言われました。
一連のIPをエクスポートしてもらいました。
阿里雲に切り替えた後、百度が実際に私の網宿のIPを覚えていたことがわかりました。本当にすごいです。
その後、ウェブマスターバックエンドを確認したところ、クロール頻度が確かに少し高かったです。
結論
- 123.125 xxx xxx
- 220.181 xxx xxx
これら2つのIP範囲はどちらも百度側のものです。原則として許可する必要があります。そして、彼らは木曜日に更新するのが好きです。
Проблема
Четверг, 5 марта 2020 года, 13:00. Трафик Baidu был аномально высоким, превышая 200 Мбит/с.
Связался с техническим персоналом Wangsu, который сказал, что краулеры Baidu создают проблемы.
Попросил их экспортировать серию IP-адресов.
После переключения на Alibaba Cloud я обнаружил, что Baidu фактически запомнил мой IP-адрес Wangsu, действительно впечатляет.
Затем я проверил бэкенд веб-мастера, и частота сканирования действительно была немного высокой.
Заключение
- 123.125 xxx xxx
- 220.181 xxx xxx
Эти два диапазона IP-адресов принадлежат Baidu. В принципе, их следует разрешить. И они любят обновляться по четвергам.
💬 讨论 / Discussion
对这篇文章有想法?欢迎在 GitHub 上发起讨论。
Have thoughts on this post? Start a discussion on GitHub.