前言
原文写的挺好的,我决定节选一部分过来
传统语言的网络层处理
服务需要同时服务N个客户端,所以传统的编程方式是采用IO复用,这样在一个线程中对N个套接字进行事件捕获,当读写事件产生后再真正read()或者write(),这样才能提高吞吐:
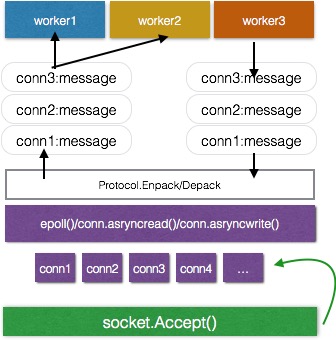
上图中:
绿色线程为接受客户端TCP链接的线程,使用阻塞的调用socket.accept(),当有新的连接到来后,将socket对象conn加入IO复用队列。
紫色线程为IO复用的阻塞调用,通常采用epoll等系统调用实现IO复用。当IO复用队列中的任意socket有数据到来,或者写缓冲区空闲时可触发epoll调用的返回,否则阻塞epoll调用。数据的实际发送和接收都在紫色线程中完成。所以为了提高吞吐,对某个socket的read和write都应该使用非阻塞的模式,这样才能最大限度的提高系统吞吐。例如,假设正在对某个socket调用阻塞的write,当数据没有完全发送完成前,write将无法返回,从而阻止了整个epoll进入下一个循环,如果这个时候其他的socket有读就绪的话,将无法第一时间响应。所以非阻塞的读写将在某个fd读写较慢的时候,立刻返回,而不会一直等到读写结束。这样才能提高吞吐。然而,采用非阻读写将大大提高编程难度。
紫色线程负责将数据进行解码并放入队列中,等待工作线程处理;工作线程有数据要发送时,也将数据放入发送队列,并通过某种机制通知紫色线程对应的socket有数据要写,进而使得数据在紫色线程中写入socket。
这种模型的编程难度主要体现在:
- 线程少(也不能太多),导致一个线程需要处理多个描述符,从而存在对描述符状态的维护问题。甚至,业务层面的会话等都需要小心维护
- 非阻塞IO调用,使描述符的状态更为复杂
- 队列的同步处理
Golang如何实现网络层
通过参考多个Golang的开源程序,笔者得出的结论是:肆无忌惮的用goroutine吧。于是一个Golang版的网络模型大致是这样的:
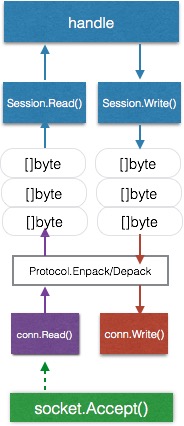
上图是单个客户端连接的服务器模块结构,同样的一个颜色代表一个协程:
绿色goroutine依然是接受TCP链接
当完成握手accept返回conn对象后,使用一个单独的goroutine来阻塞读(紫色),使用一个单独的goroutine来阻塞写(红色)
读到的数据通过解码后放入读channel,并由蓝色的goroutine来处理
需要写数据时,蓝色的goroutine将数据写入写channel,从而触发红色的goroutine编码并写入conn
可以看到,针对一个客户端,服务端至少有3个goroutine在单独为这个客户端服务。如果从线程的角度来看,简直是浪费啊,然而这就是协程的好处。这个模型很容易理解,因为跟人们的正常思维方式是一致的。并且都是阻塞的调用,所以无需维护状态。
再来看看多个客户端的情况:
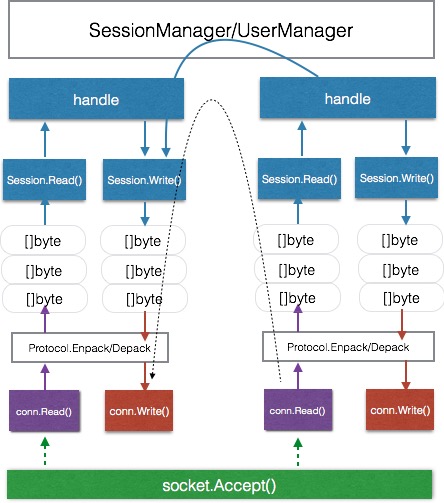
在多个客户端之间,虽然用了相同的颜色表示goroutine,但实际上他们都是独立的goroutine,可以想象goroutine的数量将是惊人的。然而,根本不用担心!这样的应用程序可能真正的线程只有几个而已。
Preface
The original article was well written, so I decided to excerpt a portion of it.
Excerpted from Golang Server Network Layer Implementation
Traditional Language Network Layer Processing
Services need to serve N clients simultaneously, so the traditional programming approach is to use IO multiplexing, which captures events for N sockets in a single thread, and then actually read() or write() when read/write events occur, in order to improve throughput:
In the above diagram:
The green thread is the thread that accepts client TCP connections, using blocking calls to socket.accept(). When a new connection arrives, the socket object conn is added to the IO multiplexing queue.
The purple thread is the blocking call for IO multiplexing, usually implemented using system calls like epoll. When any socket in the IO multiplexing queue has data arriving, or when the write buffer becomes free, the epoll call can return, otherwise the epoll call blocks. The actual sending and receiving of data are completed in the purple thread. So to improve throughput, read and write for a socket should use non-blocking mode, which maximizes system throughput. For example, suppose you’re calling a blocking write on a socket. Before the data is completely sent, write cannot return, which prevents the entire epoll from entering the next loop. If other sockets have read-ready at this time, they cannot respond immediately. So non-blocking read/write will return immediately when a fd is slow to read/write, rather than waiting until the read/write is complete. This improves throughput. However, using non-blocking read/write greatly increases programming difficulty.
The purple thread is responsible for decoding data and putting it into a queue, waiting for worker threads to process. When worker threads have data to send, they also put the data into a send queue and notify the purple thread through some mechanism that the corresponding socket has data to write, so that data is written to the socket in the purple thread.
The programming difficulty of this model is mainly reflected in:
- Few threads (and not too many), causing one thread to need to handle multiple descriptors, thus there are issues with maintaining descriptor state. Even business-level sessions need to be carefully maintained.
- Non-blocking IO calls make descriptor state more complex
- Synchronous processing of queues
How Golang Implements the Network Layer
By referring to multiple Golang open source programs, the author’s conclusion is: use goroutines recklessly. So a Golang version of the network model is roughly like this:
The above diagram shows the server module structure for a single client connection, with the same color representing a coroutine:
The green goroutine still accepts TCP connections
After the handshake completes and accept returns a conn object, use a separate goroutine to block read (purple), and use a separate goroutine to block write (red)
Read data is decoded and put into a read channel, and processed by the blue goroutine
When data needs to be written, the blue goroutine writes data to the write channel, which triggers the red goroutine to encode and write to conn
It can be seen that for a single client, the server has at least 3 goroutines serving this client alone. If viewed from a thread perspective, this is a waste, but this is the benefit of coroutines. This model is easy to understand because it’s consistent with normal thinking. And all calls are blocking, so there’s no need to maintain state.
Let’s look at the case of multiple clients:
Among multiple clients, although the same color is used to represent goroutines, they are actually independent goroutines. You can imagine the number of goroutines will be astonishing. However, there’s no need to worry! Such an application may only have a few actual threads.
前書き
原文がよく書かれていたので、一部を抜粋することにしました。
従来の言語のネットワーク層処理
サービスはN個のクライアントに同時にサービスを提供する必要があるため、従来のプログラミング方法はIO多重化を使用し、1つのスレッドでN個のソケットのイベントをキャプチャし、読み書きイベントが発生したときに実際にread()またはwrite()を実行して、スループットを向上させます:
上図では:
緑色のスレッドはクライアントTCP接続を受け入れるスレッドで、ブロッキング呼び出しsocket.accept()を使用します。新しい接続が到着すると、socketオブジェクトconnがIO多重化キューに追加されます。
紫色のスレッドはIO多重化のブロッキング呼び出しで、通常epollなどのシステム呼び出しを使用してIO多重化を実装します。IO多重化キュー内の任意のsocketにデータが到着するか、書き込みバッファが空になると、epoll呼び出しが戻り、それ以外の場合はepoll呼び出しがブロックします。データの実際の送受信は紫色のスレッドで完了します。スループットを向上させるために、socketのreadとwriteは非ブロッキングモードを使用する必要があります。これにより、システムのスループットが最大化されます。たとえば、socketでブロッキングwriteを呼び出しているとします。データが完全に送信される前に、writeは戻ることができず、epoll全体が次のループに入るのを防ぎます。この時点で他のsocketが読み取り準備完了の場合、すぐに応答できません。したがって、非ブロッキングの読み書きは、fdの読み書きが遅い場合にすぐに戻り、読み書きが完了するまで待機しません。これによりスループットが向上します。ただし、非ブロッキングの読み書きを使用すると、プログラミングの難易度が大幅に向上します。
紫色のスレッドは、データをデコードしてキューに入れ、ワーカースレッドが処理するのを待機する役割を果たします。ワーカースレッドに送信するデータがある場合、データを送信キューに入れ、何らかのメカニズムを通じて紫色のスレッドに、対応するsocketに書き込むデータがあることを通知し、データが紫色のスレッドでsocketに書き込まれるようにします。
このモデルのプログラミングの難しさは、主に以下に反映されます:
- スレッドが少ない(多すぎてもいけない)ため、1つのスレッドが複数の記述子を処理する必要があり、記述子の状態の維持に問題があります。さらに、ビジネスレベルのセッションも慎重に維持する必要があります。
- 非ブロッキングIO呼び出しにより、記述子の状態がより複雑になります
- キューの同期処理
Golangがネットワーク層を実装する方法
複数のGolangオープンソースプログラムを参照して、著者の結論は:goroutineを無制限に使用することです。したがって、Golang版のネットワークモデルはおおよそ次のようになります:
上図は、単一のクライアント接続のサーバーモジュール構造を示しており、同じ色がコルーチンを表します:
緑色のgoroutineは依然としてTCP接続を受け入れます
ハンドシェイクが完了し、acceptがconnオブジェクトを返した後、別のgoroutineを使用してブロッキング読み取り(紫色)を行い、別のgoroutineを使用してブロッキング書き込み(赤色)を行います
読み取られたデータはデコードされて読み取りchannelに入れられ、青色のgoroutineによって処理されます
データを書き込む必要がある場合、青色のgoroutineはデータを書き込みchannelに書き込み、赤色のgoroutineがエンコードしてconnに書き込むようにトリガーします
単一のクライアントに対して、サーバーには少なくとも3つのgoroutineがこのクライアント専用にサービスを提供していることがわかります。スレッドの観点から見ると、これは無駄ですが、これがコルーチンの利点です。このモデルは理解しやすく、通常の思考方法と一致しているためです。そして、すべての呼び出しがブロッキングであるため、状態を維持する必要はありません。
複数のクライアントの場合を見てみましょう:
複数のクライアント間で、同じ色を使用してgoroutineを表していますが、実際にはそれらは独立したgoroutineです。goroutineの数が驚異的になることが想像できます。しかし、心配する必要はありません!このようなアプリケーションは、実際のスレッドが数個しかない場合があります。
Предисловие
Оригинальная статья была хорошо написана, поэтому я решил выдержать из нее часть.
Выдержка из Реализация сетевого уровня сервера Golang
Обработка сетевого уровня в традиционных языках
Сервисам нужно обслуживать N клиентов одновременно, поэтому традиционный подход к программированию — использовать мультиплексирование IO, которое захватывает события для N сокетов в одном потоке, а затем фактически read() или write(), когда происходят события чтения/записи, чтобы повысить пропускную способность:
На приведенной выше диаграмме:
Зеленый поток — это поток, который принимает TCP-соединения клиентов, используя блокирующие вызовы socket.accept(). Когда приходит новое соединение, объект socket conn добавляется в очередь мультиплексирования IO.
Фиолетовый поток — это блокирующий вызов для мультиплексирования IO, обычно реализованный с использованием системных вызовов, таких как epoll. Когда любой socket в очереди мультиплексирования IO получает данные, или когда буфер записи становится свободным, вызов epoll может вернуться, иначе вызов epoll блокируется. Фактическая отправка и получение данных завершаются в фиолетовом потоке. Поэтому для повышения пропускной способности read и write для socket должны использовать неблокирующий режим, что максимизирует пропускную способность системы. Например, предположим, что вы вызываете блокирующий write на socket. Прежде чем данные будут полностью отправлены, write не может вернуться, что предотвращает вход всего epoll в следующий цикл. Если в это время другие sockets готовы к чтению, они не могут ответить немедленно. Поэтому неблокирующее чтение/запись вернется немедленно, когда fd медленно читает/пишет, а не будет ждать завершения чтения/записи. Это повышает пропускную способность. Однако использование неблокирующего чтения/записи значительно увеличивает сложность программирования.
Фиолетовый поток отвечает за декодирование данных и помещение их в очередь, ожидая обработки рабочими потоками. Когда рабочие потоки имеют данные для отправки, они также помещают данные в очередь отправки и уведомляют фиолетовый поток через какой-то механизм, что соответствующий socket имеет данные для записи, чтобы данные были записаны в socket в фиолетовом потоке.
Сложность программирования этой модели в основном отражается в:
- Мало потоков (и не слишком много), что заставляет один поток обрабатывать несколько дескрипторов, таким образом существуют проблемы с поддержанием состояния дескриптора. Даже сессии на уровне бизнеса нужно тщательно поддерживать.
- Неблокирующие вызовы IO делают состояние дескриптора более сложным
- Синхронная обработка очередей
Как Golang реализует сетевой уровень
Ссылаясь на несколько программ с открытым исходным кодом Golang, вывод автора: используйте goroutines безрассудно. Таким образом, версия сетевой модели Golang примерно такая:
Приведенная выше диаграмма показывает структуру модуля сервера для одного клиентского соединения, с тем же цветом, представляющим корутину:
Зеленая goroutine по-прежнему принимает TCP-соединения
После завершения рукопожатия и возврата conn object из accept, используйте отдельную goroutine для блокирующего чтения (фиолетовый), и используйте отдельную goroutine для блокирующей записи (красный)
Прочитанные данные декодируются и помещаются в канал чтения channel, и обрабатываются синей goroutine
Когда нужно записать данные, синяя goroutine записывает данные в канал записи channel, что запускает красную goroutine для кодирования и записи в conn
Видно, что для одного клиента сервер имеет по крайней мере 3 goroutines, обслуживающих этого клиента отдельно. Если рассматривать с точки зрения потока, это расточительно, но это преимущество корутин. Эта модель легко понять, потому что она согласуется с нормальным мышлением. И все вызовы блокирующие, поэтому нет необходимости поддерживать состояние.
Давайте посмотрим на случай нескольких клиентов:
Среди нескольких клиентов, хотя используется тот же цвет для представления goroutines, они фактически являются независимыми goroutines. Можно представить, что количество goroutines будет поразительным. Однако не нужно беспокоиться! Такое приложение может иметь только несколько фактических потоков.
💬 讨论 / Discussion
对这篇文章有想法?欢迎在 GitHub 上发起讨论。
Have thoughts on this post? Start a discussion on GitHub.